OCaml Planet
The OCaml Planet aggregates various blogs from the OCaml community. If you would like to be added, read the Planet syndication HOWTO.




 Our Experience at Tarides: Projects From Our Internships in 2023 — Tarides, Sep 15, 2023
Our Experience at Tarides: Projects From Our Internships in 2023 — Tarides, Sep 15, 2023
Internships at Tarides
We regularly have the pleasure of hosting internships where we work with engineers from all over the world on a diverse range of projects. By collaborating with people who are relatively new to the OCaml ecosystem, we get to benefit from their perspective. Seeing things with fresh eyes helps with identifying holes in documentation, gaps in workflows, as well as other ways to improve user experience.
In turn, we offer interns the opportunity to work on a project in OCaml in…
Read more...Internships at Tarides
We regularly have the pleasure of hosting internships where we work with engineers from all over the world on a diverse range of projects. By collaborating with people who are relatively new to the OCaml ecosystem, we get to benefit from their perspective. Seeing things with fresh eyes helps with identifying holes in documentation, gaps in workflows, as well as other ways to improve user experience.
In turn, we offer interns the opportunity to work on a project in OCaml in close collaboration with a mentor. This affords participants a great deal of independence, while still having the support and expertise of an experienced engineer at their disposal. During the course of their internship, participants will learn more about OCaml and strengthen their skills in functional programming. They will also have the chance to complete a project with real-world implications, contributing meaningfully to an open-source ecosystem.
Does this sound like something you would like to do? Appplications for our next round of internships open early next year, and you will be able to apply on our website around that time.
Let's check out some reports from this summer's internships, and see what the teams got up to!
Dipesh: Par_incr - A Library for Incremental Computation With Support for Parallelism
Background
I am a final year CS student from NIT Trichy. I had tried to learn Haskell in my second year but didn't really succeed. I enjoy learning about languages and their features, however, so I had learnt some OCaml by the end of my third year but not tried out any fancy features.
I found out about the internship from X (Twitter) in one of KC's tweets, but I knew about Tarides and the good work they do since I had worked with KC in the past. I messaged him to check the rules and ask if recent graduates could apply. He confirmed that they could and encouraged me to apply.
The interview itself was very pleasant; it was as if it was just me talking and discussing things with interviewers (all interviews ever should be like this!). I thought I wouldn't get it but thankfully I did.
Goal of the Project
The goal of my project was to build an incremental library with support for parallelism constructs using OCaml 5.0. Incremental computation is a software feature which attempts to optimise efficiency by only recomputing outputs that depend on changed data. The library we built, Par_incr, takes advantage of the new parallelism features in OCaml 5.0 to create an even more efficent incremental computation library.
Journey
I was somewhat familiar with OCaml so I brushed up on some concepts using the Real World OCaml textbook. OCaml.org also has a lot of resources for learning OCaml aimed at programmers of any level(beginner to advanced). For any non-trivial doubts, I would just ask my amazing mentor (Vesa) or someone else at Tarides (you can always find someone who's an expert in whatever question you have relating to OCaml) for help.
Initially, we wanted to finalise the module signature for the library. Vesa suggested a Monadic interface for the library, and it felt like the right choice.
After that was done, I started on the implementation and got something working. We wanted to check how it fared against existing libraries, so I wrote benchmarks comparing the library to current_incr and incremental.
I remember one particular bug on which I wasted almost 2 full days. I had something like this in the code:
if not is_same then t.value <- x;
Reader_list.iter readers Rsp.RNode.mark_dirtywhich should've actually been like this:
if not is_same then (t.value <- x;
Reader_list.iter readers Rsp.RNode.mark_dirty)This caused a huge performance hit because it would cause a lot of unnecessary work. You can learn more about the library from here.
Debugging this was quite fun and frustrating. It didn't even occur to me that this part could be the problem, so I was banging my head against the wall thinking I did something wrong somewhere else. I was trying out different things, but thankfully making changes to the code was enjoyable because the typechecker was always there holding my hand.
Overall it was an amazing journey. Getting to work in such an amazing environment here was a blessing for me, and I'm very grateful to have gotten this opportunity. I learnt a lot from Vesa throughout the internship and from many amazing folks at Tarides.
Challenges
The biggest challenge was to make the library performant. Since OCaml is a language with a garbage collector, you have to take special care when allocating things, since allocation isn't cheap. Another difficulty was trying to find things relating to compiler internals, so how certain things get compiled when certain optimisations kick in, etc. This is something that can be improved, but I get that it's quite difficult to keep track of documentation of large open-source compiler codebases that keep changing.
Takeaways and Best Parts
The best part was learning about optimisations, profiling, benchmarking, and improving performance, looking into assembly trying to figure out whether some things got inlined, as well as my discussions with Vesa.
The discussions with Vesa made me want to explore Emacs more, and his advice will definitely help me throughout my career. I'm also much more confident in OCaml and will probably use it whenever possible. I got to learn about all sorts of cool things being done by the Multicore team and other Tarides folks.
Shreyas: Olinkcheck
Background
I'm a final year CS student from NIT Trichy. I had never been exposed to functional programming before, but I had heard cool things about Haskell and OCaml and how Rust features were inspired by these languages. I also followed KC on Twitter from before, when I had been researching internships and professors whose work I found interesting.
When KC tweeted about openings for interns at Tarides, I opened the application doc to read about all the cool projects listed, but I didn't know any functional programming. I still applied anyways, thinking that the worst that could happen is I get rejected, no big deal.
Fast forward to a really fun interview. (No Data Structures and Algorithms? Yay! Easily my favorite interview experience so far.) It was more of a discussion than a question-and-answer.
Goal of the Project
The goal of my project was to create a tool that could be used to check for broken HTTP links, as well as present the broken link information to the user. The tool would then be integrated into OCaml.org through GitHub, to check for broken links on the website. Since OCaml.org is such a large website with lots of content, it is difficult to manually keep up with all the links. However, broken links negatively impact the user experience, and may also make pages on the website less visible to people who would otherwise be able to find the information they need.
Journey
Learning OCaml
I used these resources to learn OCaml:
- From the book 'Real World OCaml'
- From ocaml.org/learn
- By reading others' code
- Writing something and changing it until the compiler stops complaining
- UTop
- Stackoverflow
- Setting up a developer environment (I was convinced by friends at college that 'real programmers' use Vim / Emacs on Arch Linux)
Categories of Programmers and Categories in Programming
I spent some time going through library code to figure out how to actually use it. I could hack something together to work for Markdown files, and I slowly learned how to write more idiomatic OCaml (thanks to my mentor Cuihtlauac). As an imperative programmer, I was used to giving names to intermediate things, which wasn't really necessary with OCaml.
I learnt a bit about Lwt and came across the term Monad, which is, of course, as is widely known - a monoid in the category of endofunctors. (Thankfully there were much better explanations and documentation online).
Everything was going fine - I was slowly iterating on the code, making it incrementally better and adding more tests, until the first major rewrite. I was using an outdated version of a library!
That wasn't too painful, I knew what parsing code looked like already - but the structure of the document was now different.
Another library (hyper) had unfixed issues for over a year, so I swapped that out too.
I went back to my old habit of writing imperative OCaml (!) using refs. They have their place, but can be avoided when it's possible. But this was important - it helped me really imbibe the idea that functions are first class, what functional code looks like, and how I can start thinking like a functional programmer. The humble looking List.fold_left was the key to my enlightenment.
Or so I thought. I hadn't met functors yet. It is, after all, just a mapping between two categories. (No, please.) Again, Cuiht really broke it down to a point where I could start understanding what a functor in OCaml is, which eventually led me to discover the power of the OCaml module system.
Seeing it Work
After some "hacky" fixes and regular expression magic (resulting from a lot of discussions with Sabine, because I thought I hit a fundamental roadblock here and thought it might be very hard to do the project (!)), I could get it to run as a GitHub CI action, which lead to an automated pull request. I could also integrate it into Voodoo, the package documentation generator, and it is now being tested in the staging pipeline.
I've Had it All Wrong From the Beginning
By this time I had read a lot of other people's code and learnt enough from Cuiht to realise, yet again, that my code was bad. The functional programmer doesn't rely on the name of the function (what does the function v do? Or pp?). The meaning is taken from the context and the signature. So I had functions that looked like
val do_this_thing : a -> b -> c -> d -> ...with no clue as to what those arguments mean. Someone reading the code would be forced to look into the source code to understand what that means. Now my target was to have a decent looking interface when someone said #show Olinkcheck;; on utop. That's how I used other libraries, so I wanted others to be able to use mine like that too.
Biggest Challenge
My project was a practical problem, as opposed to a theoretical one like a data structure. So the challenges were also practical. Not everyone follows the same formatting while writing text-based files (let's first agree on tabs vs spaces?), and not all parsers are perfect. In the ideal world I could manipulate a syntax tree data structure which turns back into a string with the original formatting, webservers wouldn't care how many links I request from them, and there would be well defined regular expressions to find URLs amongst other text, but alas, no. None of these things are true. Text based data is convenient because of the loose requirements. Webservers can't realistically be fine with a user asking it for 7000+ links in a short time.
The Best Part
The best part for me was easily the opportunity to learn from people who are much more experienced than I am and to see something written by me be actually used in the real world.
Adithya: Domain-Safe Data Structures for Multicore OCaml
Background
I am a final year CS student at NITK Surathkal. Before this internship, I had only done a little bit of functional programming in Scala, so programming in OCaml was something very new to me. However, I was pretty excited to work on this because OCaml had only recently got Multicore support, and it was a niche area to explore.
I got to know about the internship from one of KC's tweets, and how I got to know about KC and the work he does is a pretty random incident where I needed his help to contact another professor to discuss some of my previous research internship work in a related area.
The interview experience was amongst the best ones I've had, very open ended discussions and friendly interviewers.
Goal of the Project
I was a part of the Multicore applications team and was mentored by Carine. The goal of my project was to add lock-based data structures to the Saturn library that maintains parallelism-safe data structures for Multicore OCaml.
The first step was to create a bounded queue, which is based on a Michael Scott queue. This type of queue has two locks, one for the head and one for the tail node. I also investigated fine-grained versus coarse-grained lists, double-linked lists, and finally a lock-free priority queue which was implemented on top of a lock-free skiplist.
Towards the later part of the internship, I also worked on lock-free data structures.
Journey
Initially, I started off slow since I was just getting familiar with the OCaml environment and language features. My main 2 resources to learn Ocaml was Real World OCaml and OCaml.org. Other than this, I spent a significant amount of time going through the book called The Art of Multiprocessor Programming, since that was the main reference point for my project. I also had to dive into some research papers cited in the book to get a better understanding of the implementation and some nitty-gritty details.
Over the course of the internship, I gained a lot of insights about minor details while programming for multicore systems, as well as OCaml language features that can have a significant impact on performance. Something that never struck me before was how much worse using structural equality (=) instead of physical equality (==) could be depending on the scenario.
Since I was interning on-site at the Paris office, it was very easy for me to clarify any doubts or difficulties I faced whenever required, as most people at Tarides have a very high level of expertise in OCaml and are really helpful. I often had to rewrite many functions or make major changes, but thanks to OCaml features such as static checking and type inference, it was pretty easy and relatively quick to make those modifications.
Challenges
The biggest challenge was debugging and reasoning about performance of one implementation over the other. Since I was writing parallel programs, debugging was difficult because of the many edge case scenarios that are hard to detect and can lead to deadlocks or errors in output. I remember spending an entire day sometimes finding the bug, but in the end it was really satisfying to fix it. Comparing different implementations and trying to find if any possible optimisations can be done was quite interesting and challenging.
The Best Part
Compared to my previous internships, Tarides was a unique experience since it is a pretty small company with a great culture working on some niche areas. There aren't many other places doing this kind of work. So if someone is interested in computer systems and programming languages, I would definitely recommend them to intern here. Getting the opportunity to work from the Paris office and visit Europe was definitely an unexpected yet pleasant surprise.
Want to Strengthen Your OCaml Skills?
If you're looking to learn more about functional programming in a supportive environment, you sound like an excellent candidate for our next round of internships! The next round is coming up early next year and we would be delighted if you would apply! Keep an eye on our website for more information or contact us here.
HideBeyond TypeScript: Differences Between Typed Languages — Ahrefs, Sep 14, 2023
For the past six years, I have been working with OCaml, most of this time has been spent writing code at Ahrefs to process a lot of data and show it to users in a way that makes sense.
OCaml is a language designed with types in mind. It took me some time to learn the language, its syntax, and semantics, but once I did, I noticed a significant difference in the way I would write code and colaborate with others.
Maintaining codebases became much easier, regardless of their size. And day-to-day wor…
Read more...For the past six years, I have been working with OCaml, most of this time has been spent writing code at Ahrefs to process a lot of data and show it to users in a way that makes sense.
OCaml is a language designed with types in mind. It took me some time to learn the language, its syntax, and semantics, but once I did, I noticed a significant difference in the way I would write code and colaborate with others.
Maintaining codebases became much easier, regardless of their size. And day-to-day work felt more like having a super pro sidekick that helped me identify issues in the code as I refactored it. This was a very different feeling from what I had experienced with TypeScript and Flow.
Most of the differences, especially those related to the type system, are quite subtle. Therefore, it is not easy to explain them without experiencing them firsthand while working with a real-world codebase.
However, in this post, I will attempt to compare some of the things you can do in OCaml, and explain them from the perspective of a TypeScript developer.
Before every snippet of code, we will provide links like this: (try). These links will go either to the TypeScript playground for TypeScript snippets, or to the Melange playground, for OCaml snippets. Melange is a backend for the OCaml compiler that emits JavaScript.
Without further ado, let’s go!

Photo by Bernice Tong on Unsplash
Syntax
OCaml’s syntax is very minimal (and, in my opinion, quite nice once you get used to it), but it is also quite different from the syntax in mainstream languages like JavaScript, C, or Java.
Here is a simple snippet of code in OCaml syntax (try):
let rec range a b =
if a > b then []
else a :: range (a + 1) b
let my_range = range 0 10
OCaml is built on a mathematical foundation called lambda calculus. In lambda calculus, function definitions and applications don’t use parentheses. So it was natural to design OCaml with similar syntax to that of lambda calculus.
However, the syntax might be too foreign for someone used to JavaScript. Luckily, there is a way to write OCaml programs using a different syntax which is much closer to the JavaScript one. This syntax is called Reason syntax, and it will make it much easier to get started with OCaml if you are familiar with JavaScript.
Let’s translate the example above into Reason syntax (you can translate any OCaml program to Reason syntax from the playground!):
let rec range = (a, b) =>
if (a > b) {
[];
} else {
[a, ...range(a + 1, b)];
};
let myRange = range(0, 10);
This syntax is fully supported throughout the entire OCaml ecosystem, and you can use it to build:
- native applications if you need fast startups or high speed of execution
- or compile to JavaScript if you need to run your application in the browser.
To use Reason syntax, you just need to name your source file with the .re extension instead of.ml, and you're good to go.
Since Reason syntax is widely supported and is closer to TypeScript than OCaml syntax, we will use Reason syntax for all code snippets throughout the rest of the article. Although understanding OCaml syntax has some advantages, such as allowing us to understand a larger body of source code, blog posts, and tutorials, there is absolutely no rush to do so, and you can always learn it at any time in the future. If you’re curious, we’ll provide links to the Melange playground for every snippet, so you can switch syntaxes to see how a Reason program looks in OCaml syntax, or vice versa.
Data types
OCaml has great support for data types, which are types that allow values to be contained within them. They are sometimes called algebraic data types (ADTs).
One example is tuples, which can be used to represent a point in a 2-dimensional space (try):
type point = (float, float);
let p1: point = (1.2, 4.3);
One difference with TypeScript is that OCaml tuples are their own type, different from lists or arrays, whereas in TypeScript, tuples are a subtype of arrays.
Let’s see this in practice. This is a valid TypeScript program (try):
let tuple: [string, string] = ["foo", "bar"];
let len = (a: string[]) => a.length;
let u = len(tuple)
Note how the len function is annotated to take an array of strings as input, but then we apply it and pass tuple, which has a type [string, string].
In OCaml, this will fail to compile (try):
let tuple: (string, string) = ("foo", "bar");
let len = (a: array(string)) => Array.length(a);
let u = len(tuple)
// ^^^^^
// Error This expression has type (string, string)
// but an expression was expected of type array(string)Another data type is records. Records are similar to tuples, but each “container” in the type is labeled. (try):
type point = {
x: float,
y: float,
};
let p1: point = {x: 1.2, y: 4.3};Records are similar to object types in TypeScript, but there are subtle differences in how the type system works with these types. In TypeScript, object types are structural, which means a function that works over an object type can be applied to another object type as long as they share some properties. Here’s an example ( try):
interface Todo {
title: string;
description: string;
year: number;
}
interface ShorterTodo {
title: string;
description: string;
}
const title = (todo: ShorterTodo) => console.log(todo.title);
const todo: Todo = { title: "foo", description: "bar", year: 2021 }
title(todo)In OCaml, you have a choice. Record types are nominal, so a function that takes a record type can only take values of that type. Let’s look at the same example (try):
type todo = {
title: string,
description: string,
year: int,
};
type shorterTodo = {
title: string,
description: string,
};
let title = (todo: shorterTodo) => Js.log(todo.title);
let todo: todo = {title: "foo", description: "bar", year: 2021};
title(todo);
// ^^^^
// Error This expression has type todo but an expression was expected of
// type shorterTodoBut if we want to use structural types, OCaml objects also offer that option. Here is an example using Js.t object types in Melange (try):
let printTitle = todo => {
Js.log(todo##title);
};
let todo = {"title": "foo", "description": "bar", "year": 2021};
printTitle(todo);
let shorterTodo = {"title": "foo", "description": "bar"};
printTitle(shorterTodo);To conclude the topic of ADTs, one of the most useful tools in the OCaml toolbox are variants, also known as sum types or tagged unions.
The simplest variants are similar to TypeScript enums (try):
type shape =
| Point
| Circle
| Rectangle;
The individual names of the values of a variant are called constructors in OCaml. In the example above, the constructors are Point, Circle, and Rectangle. Constructors in OCaml have a different meaning than the reserved wordconstructor in JavaScript.
Unlike TypeScript enums, OCaml does not require prefixing variant values with the type name. The type inference system will automatically infer them as long as the type is in scope.
This TypeScript code (try):
enum Shape {
Point,
Circle,
Rectangle
}
let shapes = [
Shape.Point,
Shape.Circle,
Shape.Rectangle,
];Can be written like (try):
type shape =
| Point
| Circle
| Rectangle;
let shapes = [Point, Circle, Rectangle];
Another difference is that, unlike TypeScript enums, OCaml variants can hold data for each constructor. Let’s improve the shape type to include more information about each constructor (try):
type point = (float, float);
type shape =
| Point(point)
| Circle(point, float) /* center and radius */
| Rect(point, point); /* lower-left and upper-right corners */
Something like this is possible in TypeScript using discriminated unions ( try):
type Point = { tag: 'Point'; coords: [number, number] };
type Circle = { tag: 'Circle'; center: [number, number]; radius: number };
type Rect = { tag: 'Rect'; lowerLeft: [number, number]; upperRight: [number, number] };
type Shape = Point | Circle | Rect;The TypeScript representation is slightly more verbose than the OCaml one, as we need to use object literals with a tag property to achieve the same effect. On top of that, there are greater advantages of variants that we will see just right next.
Pattern matching
Pattern matching is one of the killer features of OCaml, along with the inference engine (which we will discuss in the next section).
Let’s take the shape type we defined in the previous example. Pattern matching allows us to conditionally act on values of any type in a concise way. For example (try):
type point = (float, float);
type shape =
| Point(point)
| Circle(point, float) /* center and radius */
| Rect(point, point); /* lower-left and upper-right corners */
let area = shape =>
switch (shape) {
| Point(_) => 0.0
| Circle(_, r) => Float.pi *. r ** 2.0
| Rect((x1, y1), (x2, y2)) =>
let w = x2 -. x1;
let h = y2 -. y1;
w *. h;
};
Here is the equivalent code in TypeScript (try):
type Point = { tag: 'Point'; coords: [number, number] };
type Circle = { tag: 'Circle'; center: [number, number]; radius: number };
type Rect = { tag: 'Rect'; lowerLeft: [number, number]; upperRight: [number, number] };
type Shape = Point | Circle | Rect;
const area = (shape: Shape): number => {
switch (shape.tag) {
case 'Point':
return 0.0;
case 'Circle':
return Math.PI * Math.pow(shape.radius, 2);
case 'Rect':
const w = shape.upperRight[0] - shape.lowerLeft[0];
const h = shape.upperRight[1] - shape.lowerLeft[1];
return w * h;
default:
// Ensure exhaustive checking, even though this case should never be reached
const exhaustiveCheck: never = shape;
return exhaustiveCheck;
}
};We can observe how in OCaml, the values inside each constructor can be extracted directly from each branch of the switch statement. On the other hand, in TypeScript, we need to first check the tag, and then access the other properties of the object. Additionally, ensuring coverage of all cases in TypeScript using the never type can be more verbose, and functions may be more error-prone if we forget to handle it. In OCaml, exhaustiveness is ensured when using variants, and covering all cases requires no extra effort.
The best thing about pattern matching is that it can be used for anything: basic types like string or int, records, lists, etc.
Here is another example using pattern matching with lists (try):
let rec sumList = lst =>
switch (lst) {
/* Base case: an empty list has a sum of 0. */
| [] => 0
/* Split the list into head and tail. */
| [head, ...tail] =>
/* Recursively sum the tail of the list. */
head + sumList(tail)
};
let numbers = [1, 2, 3, 4, 5];
let result = sumList(numbers);
let () = Js.log(result);
Type annotations are optional
If we wanted to write some identity function in TypeScript, we would do something like (try):
const id: <T>(val: T) => T = val => val
function useId(id: <T>(val: T) => T) {
return [id(10)]
}
While TypeScript generics are very powerful, they lead to really verbose type annotations. As soon as our functions start taking more parameters, or increasing in complexity, the type signatures length increases accordingly.
Plus, the generic annotations have to be carried over to any other functions that compose with the original ones, making maintenance quite cumbersome in some cases.
In OCaml, the type system is based on unification of types. This differs from TypeScript, and allow to infer types for functions (even with generics) without the need of type annotations.
For example, here is how we would write the above snippet in OCaml (try):
let id = value => value;
let useId = id => [id(10)];
The compiler can infer correctly the type of useId is (int => 'a) => list('a).
With OCaml, type annotations are optional. But we can still add type annotations anywhere optionally, if we think it will be useful for documentation purposes (try):
let id: 'a => 'a = value => value;
let useId: (int => 'a) => list('a) = id => [id(10)];
I can not emphasize enough how the simplification seen above, which only involves a single function, can affect a codebase with hundreds, or thousands of more complex functions in it.
Immutability
JavaScript is a language where mutability is pervasive, and working with immutable data structures often require using third party libraries or other complex solutions.
Trying to obtain real immutable values in TypeScript is quite challenging. Historically, it has been hard to prevent mutation of properties inside objects, which was mitigated with as const.
But still, the way the type system has to be flexible to adapt for the dynamism of JavaScript can lead to “leaks” in immutable values.
Let’s see an example (try):
interface MutableValue<T> {
value: T;
}
interface ImmutableValue<T> {
readonly value: T;
}
const i: ImmutableValue<string> = { value: "hi" };
const m: MutableValue<string> = i;
m.value = "hah";As you can see, even when being strict about defining the immutable nature of the value i using TypeScript expressiveness, it is fairly easy to mutate values of that type if they happen to be passed to a function that expects a type similar in shape, but without the readonly flag.
In OCaml, immutability is the default, and it’s guaranteed. Records are immutable (like tuples, lists, and most basic types), but even if we can define mutable fields in them, something like the previous TypeScript leak is not possible (try):
type immutableValue('a) = {value: 'a}
type mutableValue('a) = {mutable value : 'a}
let i: immutableValue(string) = { value: "hi" };
let m: mutableValue(string) = i;
m.value = "hah";When trying to assign i to m we get an error: This expression has type immutableValue(string) but an expression was expected of type mutableValue(string).
No imports
This might not be as impactful of a feature as the ones we just went through, but it is really nice that in OCaml there is no need to manually import values from other modules.
In TypeScript, to use some function bar defined in a module located in../../foo.ts, we have to write:
import {bar} from "../../foo.ts";
let t = bar();In OCaml, libraries and modules in your project are all available for your program to use, so we would just write:
let t = Foo.bar()
The compiler will figure out how to find the paths to the module.
Currying
Currying is the technique of translating the evaluation of a function that takes multiple arguments into evaluating a sequence of functions, each with a single argument. It is a feature that might be more desirable for those looking into learning more about functional programming techniques.
While it is possible to use currying in TypeScript, but it becomes quite verbose (try):
const mix = (a: string) => (b: string) => b + " " + a;
const beef = mix("soaked in BBQ sauce")("beef");
const carrot = function () {
const f = mix("dip in hummus");
return f("carrot");
}();
In OCaml, all functions are curried by default. This is how a similar code would look like (try):
let mix = (a, b) => b ++ " " ++ a;
let beef = mix("soaked in BBQ sauce", "beef");
let carrot = {
let f = mix("dip in hummus");
f("carrot");
};
Build native apps that run fast
One of the best parts of OCaml is how flexible it is in the amount of places your code can run. Your applications written in OCaml can run natively on multiple devices, with very fast starts, as there is no need to start a virtual machine.
The nice thing is that OCaml does not compromise expressiveness or ergonomics to obtain really fast execution times. As this study shows, the language hits a great balance between verbosity (Y axis) and performance (X axis). It provides features like garbage collection or a powerful type system as we have seen, while producing small, fast binaries.
Write your client and server with the same language
This is not a particular feature of OCaml, as JavaScript has allowed to write applications that run in the server and the client for years. But I want to mention it because with OCaml one can obtain the upsides of sharing the same language across boundaries, together with a precise type system, a fast compiler, and an expressive and consistent functional language.
At Ahrefs, we work with the same language in frontend and backend, including tooling like build system and package manager (we wrote about it here). Having the OCaml compiler know about all our code allows us to support several number of applications and systems with a reasonably sized team, working across different timezones.
I hope you enjoyed the article. If you want to learn more about OCaml as a TypeScript developer I can recommend the Melange documentation site, which has plenty of information about how to get started. This page in particular, Melange for X developers, summarizes some of the things we have discussed, and expanding on others.
If you want to share any feedback or comments, please comment on Twitter, or join the Reason Discord to ask questions or share your progress on any project or idea built with OCaml.
Originally published at https://www.javierchavarri.com.
Beyond TypeScript: Differences Between Typed Languages was originally published in Ahrefs on Medium, where people are continuing the conversation by highlighting and responding to this story.
HideWhat the interns have wrought, 2023 edition — Jane Street, Sep 12, 2023
We’re once again at the end of our internship season, and it’s my task to provide a few highlights of what the dev interns accomplished while they were here.
The State of the Art in Functional Programming: Tarides at ICFP 2023 — Tarides, Sep 08, 2023
ICFP 2023
The 28th ACM Sigplan International Conference on Functional Programming is taking place in Seattle as I’m typing. This is the largest international research conference on functional programming, and this year’s event features fascinating keynotes (including one from OCaml’s very own Anil Madhavapeddy!), deep dives on various topics like compilation and verification, tutorials, networking opportunities, and workshops on several functional programming languages.
Out of this veritab…
Read more...ICFP 2023
The 28th ACM Sigplan International Conference on Functional Programming is taking place in Seattle as I’m typing. This is the largest international research conference on functional programming, and this year’s event features fascinating keynotes (including one from OCaml’s very own Anil Madhavapeddy!), deep dives on various topics like compilation and verification, tutorials, networking opportunities, and workshops on several functional programming languages.
Out of this veritable cornucopia of things to do and see, we’re of course most excited about the OCaml Workshop. The OCaml Users and Developers Workshop brings together a diverse group of experts and enthusiasts, from academia and businesses using OCaml in practice, to present and discuss recent developments in the OCaml ecosystem. This year, that includes presentations on everything from MetaOCaml, to an effects-based I/O in OCaml 5, and a complete OCaml compiler for WebAssembly. You can keep up with the conference on ACM Sigplan’s YouTube channel where talks are being live streamed.
At Tarides, our mission is to bring sustainable and secure software infrastructure to the world, and a powerful way to achieve this is by supporting forums that promote these goals. ICFP fosters the sharing of ideas, research, and implementation of sound functional programming principles, which is why Tarides is proud to be a silver sponsor of this year’s ICFP conference.
Several colleagues from Tarides are participating in the OCaml Workshop presenting their hard work and research on extending the language, type system, and tooling. In this post, I will give you an overview of each presentation from the Tarides team. Check out the OCaml Workshop program if you would like to explore it on your own.
Tarides at ICFP
ICFP Keynote - Programming for the Planet
Anil Madhavapeddy, our partner at the University of Cambridge, held a morning keynote speech on the role of computer systems in analysing complex data from around the globe to aid conservation efforts. Anil argues that using functional programming can lead to systems that are more resilient, predictable, and reproducible. In his presentation, he outlines the benefits of using functional programming in planetary science, and how the cross-disciplinary research his team is doing is having a tangible impact on conservation projects.
For more information on how Anil is using functional programming to help the planet, you can visit the Cambridge Centre for Carbon Credits’s website. To understand how OCaml and SpaceOS will become the new global standard for satellites, you can read our blog post on SpaceOS.
Eio 1.0 - Effects Based I/O for OCaml 5
This talk introduces the concurrency library Eio and the main features of the 1.0 release. After the release of OCaml 5, which brought support for effects and Multicore, there was demand for a new I/O library in OCaml that would unify the community around a single I/O API as well as introduce new modern features to OCaml’s I/O support.
The presentation outlines how Eio is structured, including how it uses effects so that operations don’t block the whole domain, and also highlights significant new features including modularity, integrations, and tracing. If you’re curious to know more about OCaml’s new concurrency library, check out the presentation on Eio 1.0 on Saturday the 9th of September.
Tutorial - Porting Lwt Applications to OCaml 5 and Eio
Thomas Leonard and Jon Ludlam present a tutorial on porting Lwt applications to OCaml 5 and Eio. The tutorial shows users how to incrementally convert an existing Lwt application to Eio using theLwt_eio compatibility package. Doing so will usually result in simpler code, better diagnostics, and better performance.
If you can’t attend the tutorial at ICFP, you can check out the instructions on GitHub and follow the steps. Please let us know how well the tutorial works for you, and if you have any questions don’t hesitate to ask!
Runtime Detection of Data Races in OCaml with ThreadSanitizer
This presentation from Olivier Nicole and Fabrice Buoro focuses on ThreadSanitizer (TSan) and its ability to detect data races at runtime. With the new possibilities that parallel programming in OCaml brings, it also results in new kinds of bugs. Amongst these bugs, data races present a real danger as they are difficult to detect and can lead to very unexpected results.
That’s where TSan comes in! TSan is an open source library and program instrumentation pass to reliably detect data races at runtime. The presentation covers example usages of TSan, a look into how it works, interesting insights like challenges and limitations of the project, as well as related work including static and runtime detection. There will also be a demo of how to use it in your own code. If you want to know more, have a look at the talk on TSan at ICFP.
Building a Lock-Free STM for OCaml
This talk describes the process by which the kcas library, first developed to provide a primitive atomic lock-free multi-word compare-and-set operation, was recently turned into a proper lock-free software transactional memory implementation. By using transactional memory as an abstraction, Kcas offers developers both a relatively familiar programming model and composability.
The presentation details how Kcas composes transactions, its use cases and any trade offs, as well as the process behind how its design has evolved to its current state. Discover the full details by listening to the talk on Kcas, taking place on Saturday the 9th at the OCaml Workshop.
State of the OCaml Platform in 2023
The final presentation of the workshop provides an update on the OCaml Platform, including progress over the past few years and a roadmap for future work. The OCaml Platform has grown from one tool, opam, to a complete toolchain of reliable tools for OCaml developers.
The talk covers the main milestones of the past three years, including the release of odoc and the widespread adoption of Dune, before looking at the goals for the future which include seamless editor integration and filling in gaps in the OCaml development workflows. Be sure to check out the presentation on the OCaml Platform for more context and information.
We’d Love to Hear from You!
If you’re at ICFP please come and say hi, we’d love to chat about everything OCaml with you! The OCaml Workshop is located in the Grand Crescent, and the tutorial on Eio is at St Helens. The talks are available on ACM Sigplan’s youtube channel for remote viewing.
You can always tweet at us, or chat with the larger OCaml community on Discuss. Look out for more content on Tarides.com coming your way soon and sign up to our newsletter for up to date content - until next time!
HideRelease of Frama-Clang 0.0.14 — Frama-C, Sep 07, 2023
Oxidizing OCaml: Data Race Freedom — Jane Street, Sep 01, 2023
OCaml with Jane Street extensions is available from our public opam repo. Only a slice of the features described in this series are currently implemented.
Your Programming Language and its Impact on the Cybersecurity of Your Application — Tarides, Aug 17, 2023
Did you know that the programming language you use can have a huge impact on the cybersecurity of your applications?
In a 2022 meeting of the Cybersecurity Advisory Committee, the Cybersecurity and Infrastructure Security Agency’s Senior Technical Advisor Bob Lord commented that: “About two-thirds of the vulnerabilities that we see year after year, decade after decade” are related to memory management issues.
Memory Unsafe Languages
One can argue that cyber vulnerabilities are simply a fac…
Read more...Did you know that the programming language you use can have a huge impact on the cybersecurity of your applications?
In a 2022 meeting of the Cybersecurity Advisory Committee, the Cybersecurity and Infrastructure Security Agency’s Senior Technical Advisor Bob Lord commented that: “About two-thirds of the vulnerabilities that we see year after year, decade after decade” are related to memory management issues.
Memory Unsafe Languages
One can argue that cyber vulnerabilities are simply a fact of life in the modern online world, which is why every application needs robust cyber security protections (applications, libraries, middleware, operating systems, tools, etc.). While this argument is not technically incorrect, there are still significant differences in the intrinsic security levels of different programming languages.
Computing devices today have access to huge amounts of memory in order to store, process, and retrieve information. Programming languages are used to describe the operations that a device needs to perform. The computer then interprets these operations to access and manipulate memory (of course, programming languages do many other things as well).
Among the various language paradigms, there are some widely used ones such as C and C++ that allow the developer to directly manipulate hardware memory. However, when a programmer writes code using these languages, it could result in attackers gaining access to hardware, stealing data, denying access to the user, and performing other malicious activities. Hence, these programming languages are termed as “memory-unsafe” languages.
Impact of Memory Exploits
Around 60-70% of cyber attacks (attacks on applications, the operating system, etc.) are due to the use of these memory-unsafe programming languages.
This remains true for any computing platform. Memory issues represented around 65% of critical security risks in the Chrome browser and Android operating system. Similarly, memory unsafety issues also represented around 65% of total reported issues for the Linux kernel in 2019. The Chromium web browser project has also reported that 70% of high-severity security bugs were related to memory safety. In iOS 12, 66.3% of vulnerabilities were related to handling memory.
The Solution: Memory Safety
All this begs the question: is there a solution that can eliminate risks that exist due to a programming language’s design, or is the only solution to use several layers of cybersecurity protection (code hardening, firewalls, etc.)?
Many cybersecurity and technology experts recommend using a “memory-safe” programming language, where a number of validation checks are performed during the translation from the human-readable programming language to the format that the machine reads. Many such programming languages exist, giving the developers several choices, for example: Go, Java, Ruby, Swift, and OCaml are all memory safe.
Does this mean that memory-safe languages are protected from all cyber attacks? No, but 60-70% of attacks are by design not permitted by the language. That is why most memory safe languages also offer crypto libraries, formal verification, and more in order to ensure the best possible cyber protection in addition to the strong protection the language itself provides. Of course, you also need to follow industry best practices for physical security, access controls, firewalls, data protection techniques, and other defence mechansims for people-centric security.
If you already work using memory-safe programming languages, you are on the right track. If you don’t, we would be glad to tell you why companies like Jane Street, Tezos, Microsoft, Tarides, and Meta use OCaml to provide not only the best possible cybersecurity but also exceptional coding flexibility.
Don’t hesitate to contact us via sales@tarides.com for more information or with any questions you may have.
References
-
Report: Future of Memory Safety. https://advocacy.consumerreports.org/research/report-future-of-memory-safety/
-
NSA releases guidance on how to protect against software memory safety issues. https://www.nsa.gov/Press-Room/News-Highlights/Article/Article/3215760/nsa-releases-guidance-on-how-to-protect-against-software-memory-safety-issues/
-
The Federal Government is moving on memory safety for Cybersecurity. https://www.nextgov.com/cybersecurity/2022/12/federal-government-moving-memory-safety-cybersecurity/381275/
-
Memory Safety Convening Report 1.1. https://advocacy.consumerreports.org/wp-content/uploads/2023/01/Memory-Safety-Convening-Report-1-1.pdf
-
Chromium project memory safety. https://www.chromium.org/Home/chromium-security/memory-safety/
On indefinite truth values — Andrej Bauer, Aug 12, 2023
In a discussion following a MathOverflow answer by Joel Hamkins, Timothy Chow and I got into a chat about what it means for a statement to “not have a definite truth value”. I need a break from writing the paper on countable reals (coming soon in a journal near you), so I thought it would be worth writing up my view of the matter in a blog post.
How are we to understand the statement “the Riemann hypothesis (RH) does not have a definite truth value”?
Let me first address two possible…
Read more...In a discussion following a MathOverflow answer by Joel Hamkins, Timothy Chow and I got into a chat about what it means for a statement to “not have a definite truth value”. I need a break from writing the paper on countable reals (coming soon in a journal near you), so I thought it would be worth writing up my view of the matter in a blog post.
How are we to understand the statement “the Riemann hypothesis (RH) does not have a definite truth value”?
Let me first address two possible explanations that in my view have no merit.
First, one might suggest that “RH does not have a definite truth value” is the same as “RH is neither true nor false”. This is nonsense, because “RH is neither true nor false” is the statement $\neg \mathrm{RH} \land \neg\neg\mathrm{RH}$, which is just false by the law of non-contradiction. No discussion here, I hope. Anyone claiming “RH is neither true nor false” must therefore mean that they found a paradox.
Second, it is confusing and even harmful to drag into this discussion syntactically invalid, ill-formed, or otherwise corrupted statements. To say something like “$(x + ( - \leq 7$ has no definite truth value” is meaningless. The notion of truth value does not apply to arbitrary syntactic garbage. And even if one thinks this is a good idea, it does not apply to RH, which is a well-formed formula that can be assigned meaning.
Having disposed of ill-fated attempts, let us ask what the precise mathematical meaning of the statement might be. It is important to note that we are discussing semantics. The truth value of a sentence $P$ is an element $I(P) \in B$ of some Boolean algebra $(B, 0, 1, {\land}, {\lor}, {\lnot})$, assigned by an interpretation function $I$. (I am assuming classical logic, but nothing really changes if we switch to intuitionistic logic, just replace Boolean algebras with Heyting algebras.) Taking this into account, I can think of three ways of explaining “RH does not have a definite truth value”:
-
The truth value $I(\mathrm{RH})$ is neither $0$ nor $1$. (Do not confuse this meta-statement with the object-statement $\neg \mathrm{RH} \land \neg\neg\mathrm{RH}$.) Of course, for this to happen one has to use a Boolean algebra that contains something other than $0$ and $1$.
-
The truth value of $I(\mathrm{RH})$ varies, depending on the model and the interpretation function. An example of this phenomenon is the continuum hypothesis, which is true in some set-theoretic models and false in others.
-
The interpretation function $I$ fails to assign a truth value to $\mathrm{RH}$.
Assuming we have set up sound and complete semantics, the first and the second reading above both amount to undecidability of RH. Indeed, if the truth value of RH is not $1$ across all models then RH is not provable, and if it is not fixed at $0$ then it is not refutable, hence it is undecidable. Conversely, if RH is undecidable then its truth value in the Lindenbaum-Tarski algebra is neither $0$ nor $1$. We may quotient the algebra so that the value becomes true or false, as we wish.
The third option says that one has got a lousy interpretation function and should return to the drawing board.
In some discussions “RH does not have a definite truth value” seems to take on an anthropocentric component. The truth value is indefinite because knowledge of it is lacking, or because there is a cognitive barrier to comprehending the statement, etc. I find these just as unappealing as the Brouwerian counterexamples arguing in favor of intuitionistic logic.
The only realm in which I reasonably comprehend “$P$ does not have a definite truth value” is pre-mathematical, or even philosophical. It may be the case that $P$ refers to pre-mathematical concepts lacking precise formal description, or whose existing formal descriptions are considered problematic. This situation is similar to the third one above, but cannot be just dismissed as technical deficiency. An illustrative example is Solomon Feferman's Does mathematics need new axioms? and the discussion found therein on the meaningfulness and the truth value of the continuum hypothesis. (However, I am not aware of anyone seriously arguing that the mathematical meaning of Riemann hypothesis is contentious.)
So, what do I mean by “RH does not have a definite truth value”? Nothing, I would never say that and I do not understand what it is supposed to mean. RH clearly has a definite truth value, in each model, and with some luck we are going to find out which one. (To preempt a counter-argument: the notion of “standard model” is a mystical concept, while those stuck in an “intended model” suffer from lack of imagination.)
HideKcas: Building a Lock-Free STM for OCaml (2/2) — Tarides, Aug 10, 2023
This is the follow-up post continuing the discussion of the development of Kcas. Part 1 discussed the development done on the library to improve performance and add a transaction mechanism that makes it easy to compose atomic operations without really adding more expressive power.
In this part we'll discuss adding a fundamentally new feature to Kcas that makes it into a proper STM implementation.
Get Busy Waiting
If shared memory locations and transactions over them essentially replace traditio…
Read more...This is the follow-up post continuing the discussion of the development of Kcas. Part 1 discussed the development done on the library to improve performance and add a transaction mechanism that makes it easy to compose atomic operations without really adding more expressive power.
In this part we'll discuss adding a fundamentally new feature to Kcas that makes it into a proper STM implementation.
Get Busy Waiting
If shared memory locations and transactions over them essentially replace traditional mutexes, then one might ask what replaces condition variables. It is very common in concurrent programming for threads to not just want to avoid stepping on each other's toes, or the I of ACID, but to actually prefer to follow in each other's footsteps. Or, to put it more technically, wait for events triggered or data provided by other threads.
Following the approach introduced in the paper
Composable Memory Transactions,
I implemented a retry mechanism that allows a transaction to essentially wait on
arbitrary conditions over the state of shared memory locations. A transaction
may simply raise an exception,
Retry.Later,
to signal to the commit mechanism that a transaction should only be retried
after another thread has made changes to the shared memory locations examined by
the transaction.
A trivial example would be to convert a non-blocking take on a queue to a blocking operation:
let take_blocking ~xt queue =
match Queue.Xt.take_opt ~xt queue with
| None -> Retry.later ()
| Some elem -> elemOf course, the
Queue
provided by kcas_data already has a blocking take which essentially results in the above
implementation.
Perhaps the main technical challenge in implementing a retry mechanism in multicore OCaml is that it should perform blocking in a scheduler friendly manner such that other fibers, as in Eio, or tasks, as in Domainslib, are not prevented from running on the domain while one of them is blocked. The difficulty with that is that each scheduler potentially has its own way for suspending a fiber or waiting for a task.
To solve this problem such that we can provide an updated and convenient blocking experience, we introduced a library that provides a domain-local-await mechanism, whose interface is inspired by Arthur Wendling's proposal for the Saturn library. The idea is simple. Schedulers like Eio and Domainslib install their own implementation of the blocking mechanism, stored in a domain local variable, and then libraries like Kcas can obtain the mechanism to block in a scheduler friendly manner. This allows blocking abstractions to not only work on one specific scheduler, but also allows blocking abstractions to work across different schedulers.
Another challenge is the desire to support both conjunctive and disjunctive combinations of transactions. As explained in the paper Composable Memory Transactions, this in turn requires support for nested transactions. Consider the following attempt at a conditional blocking take from a queue:
let non_nestable_take_if ~xt predicate queue =
let x = Queue.Xt.take_blocking ~xt queue in
if not (predicate x) then
Retry.later ();
xIf one were to try to use the above to take an element from the
first
of two queues
Xt.first [
non_nestable_take_if predicate queue_a;
non_nestable_take_if predicate queue_b;
]one would run into the following problem: while only a value that passes the predicate would be returned, an element might be taken from both queues.
To avoid this problem, we need a way to roll back changes recorded by a transaction attempt. The way Kcas supports this is via an explicit scoping mechanism. Here is a working (nestable) version of conditional blocking take:
let take_if ~xt predicate queue =
let snap = Xt.snapshot ~xt in
let x = Queue.Xt.take_blocking ~xt queue in
if not (predicate x) then
Retry.later (Xt.rollback ~xt snap);
xFirst a
snapshot
of the transaction log is taken and then, in case the predicate is not
satisfied, a
rollback
to the snapshot is performed before signaling a retry. The obvious disadvantage of
this kind of explicit approach is that it requires more care from the
programmer. The advantage is that it allows the programmer to explicitly scope
nested transactions and perform rollbacks only when necessary and in a more
fine-tuned manner, which can allow for better performance.
With properly nestable transactions one can express both conjunctive and disjunctive compositions of conditional transactions.
As an aside, having talked about the splay tree a few times in my previous post, I should mention that the implementation of the rollback operation using the splay tree also worked out surprisingly nicely. In the general case, a rollback may have an effect on all accesses to shared memory locations recorded in a transaction log. This means that, in order to support rollback, worst case linear time cost in the number of locations accessed seems to be the minimum — no matter how transactions might be implemented. A single operation on a splay tree may already take linear time, but it is also possible to take advantage of the tree structure and sharing of the immutable spine of splay trees and stop early as soon as the snapshot and the log being rolled back are the same.
Will They Come
Blocking or retrying a transaction indefinitely is often not acceptable. The transaction mechanism with blocking is actually already powerful enough to support timeouts, because a transaction will be retried after any location accessed by the transaction has been modified. So, to have timeouts, one could create a location, make it so that it is changed when the timeout expires, and read that location in the transaction to determine whether the timeout has expired.
Creating, checking, and also cancelling timeouts manually can be a lot of work.
For this reason Kcas was also extended with direct support for timeouts. To
perform a transaction with a timeout one can simply explicitly specify a
timeoutf in seconds:
let try_take_in ~seconds queue =
Xt.commit ~timeoutf:seconds { tx = Queue.Xt.take_blocking queue }Internally Kcas uses the domain-local-timeout library for timeouts. The OCaml standard library doesn't directly provide a timeout mechanism, but it is a typical service provided by concurrent schedulers. Just like with the previously mentioned domain local await, the idea with domain local timeout is to allow libraries like Kcas to tap into the native mechanism of whatever scheduler is currently in use and to do so conveniently without pervasive parameterisation. More generally this should allow libraries like Kcas to be scheduler agnostic and help to avoid duplication of effort.
Hollow Man
Let's recall the features of Kcas transactions briefly.
First of all, passing the transaction ~xt through the computation allows
sequential composition of transactions:
let bind ~xt a b =
let x = a ~xt in
b ~xt xThis also gives conjunctive composition as a trivial consequence:
let pair ~xt a b =
(a ~xt, b ~xt)Nesting, via
snapshot
and
rollback,
allows conditional composition:
let if_else ~xt predicate a b =
let snap = Xt.snapshot ~xt in
let x = a ~xt in
if predicate x then
x
else begin
Xt.rollback ~xt snap;
b ~xt
endNesting combined with blocking, via the
Retry.Later
exception, allows disjunctive composition
let or_else ~xt a b =
let snap = Xt.snapshot ~xt in
match a ~xt with
| x -> x
| exception Retry.Later ->
Xt.rollback ~xt snap;
b ~xtof blocking transactions, which is also supported via the
first
combinator.
What is Missing?
The limits of my language mean the limits of my world. — Ludwig Wittgenstein
The main limitation of transactions is that they are invisible to each other. A transaction does not directly modify any shared memory locations and, once it does, the modifications appear as atomic to other transactions and outside observers.
The mutual invisibility means that
rendezvous between two
(or more) threads cannot be expressed as a pair of composable transactions. For
example, it is not possible to implement synchronous message passing as can be
found e.g. in
Concurrent ML,
Go, and various other languages and libraries, including zero
capacity Eio
Streams,
as simple transactions with a signature such as follows:
module type Channel = sig
type 'a t
module Xt : sig
val give : xt:'x Xt.t -> 'a t -> 'a -> unit
val take : xt:'x Xt.t -> 'a t -> 'a
end
endLanguages such as Concurrent ML and Go allow disjunctive composition of such synchronous message passing operations and some other libraries even allow conjunctive, e.g. CHP, or even sequential composition, e.g. TE and Reagents, of such message passing operations.
Although the above Channel signature is unimplementable, it does not mean that
one could not implement a non-compositional Channel
module type Channel = sig
type 'a t
val give : 'a t -> 'a -> unit
val take : 'a t -> 'a
endor implement a compositional message passing model that allows such operations to be composed. Indeed, both the CHP and TE libraries were implemented on top of Software Transactional Memory with the same fundamental invisibility of transactions. In other words, it is possible to build a new composition mechanism, distinct from transactions, by using transactions. To allow such synchronisation between threads requires committing multiple transactions.
Torn Reads
The k-CAS-n-CMP algorithm underlying Kcas ensures that it is not possible to read uncommitted changes to shared memory locations and that an operation can only commit successfully after all of the accesses taken together have been atomic, i.e. strictly serialisable or both linearisable and serialisable in database terminology. These are very strong guarantees and make it much easier to implement correct concurrent algorithms.
Unfortunately, the k-CAS-n-CMP algorithm does not prevent one specific concurrency anomaly. When a transaction reads multiple locations, it is possible for the transaction to observe an inconsistent state when other transactions commit changes between reads of different locations. This is traditionally called read skew in database terminology. Having observed such an inconsistent state, a Kcas transaction cannot succeed and must be retried.
Even though a transaction must retry after having observed read skew, unless taken into account, read skew can still cause serious problems. Consider, for example, the following transaction:
let unsafe_subscript ~xt array index =
let a = Xt.get ~xt array in
let i = Xt.get ~xt index in
a.(i)The assumption is that the array and index locations are always updated
atomically such that the subscript operation should be safe. Unfortunately due
to read skew the array and index might not match and the subscript operation
could result in an "index out of bounds" exception.
Even more subtle problems are possible. For example, a balanced binary search
tree implementation using
rotations can, due to read skew,
be seen to have a cycle. Consider the below diagram. Assume that a lookup for
node 2 has just read the link from node 3 to node 1. At that point another
transaction commits a rotation that makes node 3 a child of node 1. As the
lookup reads the link from node 1 it leads back to node 3 creating a cycle.

There are several ways to deal with these problems. It is, of course, possible to use ad hoc techniques, like checking invariants manually, within transactions. The Kcas library itself addresses these problems in a couple of ways.
First of all, Kcas performs periodic validation of the entire transaction log
when an access, such as get or set, of a shared memory location is made
through the transaction log. It would take quadratic time to validate the entire
log on every access. To avoid changing the time complexity of transactions, the
number of accesses between validations is doubled after each validation.
Periodic validation is an effective way to make loops that access shared memory
locations, such as the lookup of a key from a binary search tree, resistant
against read skew. Such loops will eventually be aborted on some access and will
then be retried. Periodic validation is not effective against problems that
might occur due to non-transactional operations made after reading inconsistent
state. For those cases an explicit
validate
operation is provided that can be used to validate that the accesses of
particular locations have been atomic:
let subscript ~xt array index =
let a = Xt.get ~xt array in
let i = Xt.get ~xt index in
(* Validate accesses after making them: *)
Xt.validate ~xt index;
Xt.validate ~xt array;
a.(i)It is entirely fair to ask whether it is acceptable for an STM mechanism to allow read skew. A candidate correctness criterion for transactional memory called "opacity", introduced in the paper On the correctness of transactional memory, does not allow it. The trade-off is that the known software techniques to provide opacity tend to introduce a global sequential bottleneck, such as a global transaction version number accessed by every transaction, that can and will limit scalability especially when transactions are relatively short, which is usually the case.
At the time of writing this there are several STM implementations that do not provide opacity. The current Haskell STM implementation, for example, introduced in 2005, allows similar read skew. In Haskell, however, STM is implemented at the runtime level and transactions are guaranteed to be pure by the type system. This allows the Haskell STM runtime to validate transactions when switching threads. Nevertheless there have been experiments to replace the Haskell STM using algorithms that provide opacity as described in the paper Revisiting software transactional memory in Haskell, for example. The Scala ZIO STM also allows read skew. In his talk Transactional Memory in Practice, Brett Hall describes their experience in using a STM in C++ that also allows read skew.
It is not entirely clear how problematic it is to have to account for the possibility of read skew. Although I expect to see read skew issues in the future, the relative success of the Haskell STM would seem to suggest that it is not necessarily a show stopper. While advanced data structure implementations tend to have intricate invariants and include loops, compositions of transactions using such data structures, like the LRU cache implementation, tend to be loopless and relatively free of such invariants and work well.
Tomorrow May Come
At the time of writing this, the kcas and kcas_data packages are still
marked experimental, but are very close to being labeled 1.0.0. The core Kcas
library itself is more or less feature complete. The Kcas data library, by its
nature, could acquire new data structure implementations over time, but there is
one important feature missing from Kcas data — a bounded queue.
It is, of course, possible to simply compose a transaction that checks the length of a queue. Unfortunately that would not perform optimally, because computing the exact length of a queue unavoidably requires synchronisation between readers and writers. A bounded queue implementation doesn't usually need to know the exact length — it only needs to have a conservative approximation of whether there is room in the queue and then the computation of the exact length can be avoided much of the time. Ideally the default queue implementation would allow an optional capacity to the specified. The challenge is to implement the queue without making it any slower in the unbounded case.
Less importantly the Kcas data library currently does not provide an ordered map nor a priority queue. Those serve use cases that are not covered by the current selection of data structures. For an ordered map something like a WAVL tree could be a good starting point for a reasonably scalable implementation. A priority queue, on the other hand, is more difficult to scale, because the top element of a priority queue might need to be examined or even change on every mutation, which makes it a sequential bottleneck. On the other hand, updating elements far from the top shouldn't require much synchronisation. Some sort of two level scheme like a priority queue of per domain priority queues might provide best of both worlds.
But Why?
If you look at a typical textbook on concurrent programming it will likely tell you that the essence of concurrent programming boils down to two (or three) things:
- independent sequential threads of control, and
- mechanisms for threads to communicate and synchronise.
The first bullet on that list has received a lot of focus in the form of libraries like Eio and Domainslib that utilise OCaml's support for algebraic effects. Indeed, the second bullet is kind of meaningless unless you have threads. However, that does not make it less important.
Programming with threads is all about how threads communicate and synchronise with each other.
A survey of concurrent programming techniques could easily fill an entire book, but if you look at most typical programming languages, they provide you with a plethora of communication and synchronisation primitives such as
- atomic operations,
- spin locks,
- barriers and count down latches,
- semaphores,
- mutexes and condition variables,
- message queues,
- other concurrent collections,
- and more.
The main difficulty with these traditional primitives is their relative lack of composability. Every concurrency problem becomes a puzzle whose solution is some ad hoc combination of these primitives. For example, given a concurrent thread safe stack and a queue it may be impossible to atomically move an element from the stack to the queue without wrapping both behind some synchronisation mechanism, which also likely reduces scalability.
There are also some languages based on asynchronous message passing with the ability to receive multiple messages selectively using both conjunctive and disjunctive patterns. A few languages are based on rendezvous or synchronous message passing and offer the ability to disjunctively and sometimes also conjunctively select between potential communications. I see these as fundamentally different from the traditional primitives as the number of building blocks is much smaller and the whole is more like unified language for solving concurrency problems rather than just a grab bag of non-composable primitives. My observation, however, has been that these kind of message passing models are not familiar to most programmers and can be challenging to program with.
As an aside, why should one care about composability? Why would anyone care about being able to e.g. disjunctively either pop an element from a stack or take an element from a queue, but not both, atomically? Well, it is not about stacks and queues, those are just examples. It is about modularity and scalability. Being able to, in general, understand independently developed concurrent abstractions on their own and to also combine them to form effective and efficient solutions to new problems.
Another approach to concurrent programming is transactions over mutable data structures whether in the form of databases or Software Transactional Memory (STM). Transactional databases, in particular, have definitely proven to be a major enabler. STM hasn't yet had a similar impact. There are probably many reasons for that. One probable reason is that many languages already offered a selection of familiar traditional primitives and millions of lines of code using those before getting STM. Another reason might be that attempts to provide STM in a form where one could just wrap any code inside an atomic block and have it work perfectly proved to be unsuccessful. This resulted in many publications and blog posts, e.g. A (brief) retrospective on transactional memory, discussing the problems resulting from such doomed attempts and likely contributed to making STM seem less desirable.
However, STM is not without some success. More modest, and more successful, approaches either strictly limit what can be performed atomically or require the programmer to understand the limits and program accordingly. While not a panacea, STM provides both composability and a relatively simple and familiar programming model based on mutable shared memory locations.
Crossroads
Having just recently acquired the ability to have multiple domains running in parallel, OCaml is in a unique position. Instead of having a long history of concurrent multicore programming we can start afresh.
What sort of model of concurrent programming should OCaml offer?
One possible road for OCaml to take would be to offer STM as the go-to approach for solving most concurrent programming problems.
Until Next Time
I've had a lot of fun working on Kcas. I'd like to thank my colleagues for putting up with my obsession to work on it. I also hope that people will find Kcas and find it useful or learn something from it!
HideKcas: Building a Lock-Free STM for OCaml (1/2) — Tarides, Aug 07, 2023
In the past few months I've had the pleasure of working on the Kcas library. In this and a follow-up post, I will discuss the history and more recent development process of optimising Kcas and turning it into a proper Software Transactional Memory (STM) implementation for OCaml.
While this is not meant to serve as an introduction to programming with Kcas, along the way we will be looking at a few code snippets. To ensure that they are type correct — the best kind of correct* — I'll use the M…
Read more...In the past few months I've had the pleasure of working on the Kcas library. In this and a follow-up post, I will discuss the history and more recent development process of optimising Kcas and turning it into a proper Software Transactional Memory (STM) implementation for OCaml.
While this is not meant to serve as an introduction to programming with Kcas, along the way we will be looking at a few code snippets. To ensure that they are type correct — the best kind of correct* — I'll use the MDX tool to test them. So, before we continue, let's require the libraries that we will be using:
# #require "kcas"
# open Kcas
# #require "kcas_data"
# open Kcas_dataAll right, let us begin!
Origins
Contrary to popular belief, the name "Kcas" might not be an abbreviation of KC and Sadiq. Sadiq once joked "I like that we named the library after KC too." — two early contributors to the library. The Kcas library was originally developed for the purpose of implementing Reagents for OCaml and is an implementation of multi-word compare-and-set, often abbreviated as MCAS, CASN, or — wait for it — k-CAS.
But what is this multi-word compare-and-set?
Well, it is a tool for designing lock-free algorithms that allows atomic operations to be performed over multiple shared memory locations. Hardware traditionally only supports the ability to perform atomic operations on individual words, i.e. a single-word compare-and-set (CAS). Kcas basically extends that ability, through the use of intricate algorithms, so that it works over any number of words.
Suppose, for example, that we are implementing operations on doubly-linked
circular lists. Instead of using a mutable field, ref, or Atomic.t, we'd use
a shared memory location, or
Loc.t,
for the pointers in our node type:
type 'a node = {
succ: 'a node Loc.t;
pred: 'a node Loc.t;
datum: 'a;
}To remove a node safely we want to atomically update the succ and pred
pointers of the predecessor and successor nodes and to also update the succ
and pred pointers of a node to point to the node itself, so that removal
becomes an idempotent operation.
Using a multi-word compare-and-set one could implement the remove operation as
follows:
let rec remove ?(backoff = Backoff.default) node =
(* Read pointer to the predecessor node and... *)
let pred = Loc.get node.pred in
(* ..check whether the node has already been removed. *)
if pred != node then
let succ = Loc.get node.succ in
let ok = Op.atomically [
(* Update pointers in this node: *)
Op.make_cas node.succ succ node;
Op.make_cas node.pred pred node;
(* Update pointers to this node: *)
Op.make_cas pred.succ node succ;
Op.make_cas succ.pred node pred;
] in
if not ok then
(* Someone modified the list around us, so backoff and retry. *)
remove ~backoff:(Backoff.once backoff) nodeThe list given to
Op.atomically
contains the individual compare-and-set operations to perform. A single
Op.make_cas loc expected desired
operation specifies to compare the current value of a location with the expected
value and, in case they are the same, set the value of the location to the
desired value.
Programming like this is similar to programming with single-word compare-and-set except that the operation is extended to being able to work on multiple words. It does get the job done, but I feel it is fair to say that this is a low level tool only suitable for experts implementing lock-free algorithms.
Getting Curious
I became interested in working on the Kcas library after Bartosz Modelski asked me to review a couple of PRs to Kcas. As it happens, I had implemented the same k-CAS algorithm, based on the paper A Practical Multi-Word Compare-and-Swap Operation, a few years earlier in C++ as a hobby project. I had also considered implementing Reagents and had implemented a prototype library based on the Transactional Locking II (TL2) algorithm for software transactional memory (STM) in C++ as another hobby project. While reviewing the library, I could see some potential for improvements.
Fine Grained Competition
One of the issues in the Kcas Github repo mentioned a new paper on
Efficient Multi-word Compare and Swap.
It was easy to adapt the new algorithm, which can even be seen as a
simplification of the previous algorithm, to OCaml. Compared to the previous
algorithm, which took 3k+1 single word CAS operations per k-CAS, the new
algorithm only took k+1 single word CAS operations and was much faster. This
basically made k-CAS potentially competitive with fine grained locking
approaches, that also tend to require roughly the equivalent of one CAS per
word, used in many STM implementations.
Two Birds with One Stone
Both the original algorithm and the new algorithm require the locations being
updated to be in some total order. Any ordering that is used consistently in all
potentially overlapping operations would do, but the shared memory locations
created by Kcas also include a unique integer id, which can be used for ordering
locations. Initially Kcas required the user to sort the list of CAS operations.
Later an internal sorting step, that was performed by default by essentially
calling List.sort and taking
linearithmic
O(n*log(n)) time, was added to Kcas to make the interface less error prone.
This works, but it is possible to do better. Back when I implemented a TL2
prototype in C++ as a hobby project, I had used a
splay tree to record accesses of
shared memory locations. Along with the new algorithm, I also changed Kcas to
use a splay tree to store the operations internally. The splay tree was
constructed from the list of operations given by the user and then the splay
tree, instead of a list, would be traversed during the main algorithm.
You could ask what makes a splay tree interesting for this particular use case.
Well, there are a number of reasons. First of all, the new algorithm requires
allocating internal descriptors for each operation anyway, because those
descriptors are essentially consumed by the algorithm. So, even when the sorting
step would be skipped, an ordered data structure of descriptors would still need
to be allocated. However, what makes a splay tree particularly interesting for
this purpose is that, unlike most self-balancing trees, it can perform a
sequence of n accesses in linear time O(n). This happens, for example, when
the accesses are in either ascending or descending order. In those cases, as
shown in the diagram below, the result is either a left or right leaning tree,
respectively, much like a list.

This means that a performance conscious user could simply make sure to provide
the locations in either order and the internal tree would be constructed in
linear time and could then be traversed, also in linear time, in ascending
order. For the general case a splay tree also guarantees the same linearithmic
O(n*log(n)) time as sorting.
With some fast path optimisations for preordered sequences the splay tree construction was almost free and the flag to skip the by default sorting step could be removed without making performance worse.
Keeping a Journal
Having the splay tree also opened the possibility of implementing a higher level transactional interface.
But what is a transaction?
Well, a transaction in Kcas is essentially a function that records a log of accesses, i.e. reads and writes, to shared memory locations. When accessing a location for the first time, whether for reading or for writing, the value of that location is read and stored in the log. Then, instead of reading the location again or writing to it, the entry for the location is looked up from the log and any change is recorded in the entry. So, a transaction does not directly mutate shared memory locations. A transaction merely reads their initial values and records what the effects of the accesses would be.
Recall the example of how to remove a node from a doubly-linked circular list. Using the transactional interface of Kcas, we could write a transaction to remove a node as follows:
let remove ~xt node =
(* Read pointers to the predecessor and successor nodes: *)
let pred = Xt.get ~xt node.pred in
let succ = Xt.get ~xt node.succ in
(* Update pointers in this node: *)
Xt.set ~xt node.succ node;
Xt.set ~xt node.pred node;
(* Update pointers to this node: *)
Xt.set ~xt pred.succ succ;
Xt.set ~xt succ.pred predThe labeled argument, ~xt, refers to the transaction log. Transactional
operations like
get
and
set
are then recorded in that log. To actually remove a node, we need to commit the
transaction
Xt.commit { tx = remove node }which repeatedly calls the transaction function, tx, to record a transaction
log and attempts to atomically perform it until it succeeds.
Notice that remove is no longer recursive. It doesn't have to account for
failure or perform a backoff. It is also not necessary to know or keep track of
what the previous values of locations were. All of that is taken care of for us
by the transaction log and the
commit
function. But, I digress.
Having the splay tree made the implementation of the transactional interface
straightforward. Transactional operations would just use the splay tree to
lookup and record accesses of shared memory locations. The
commit
function just calls the transaction with an empty splay tree and then passes the
resulting tree to the internal k-CAS algorithm.
But why use a splay tree? One could suggest e.g. using a hash table for the
transaction log. Accesses of individual locations would then be constant time.
However, a hash table doesn't sort the entries, so we would need something more
for that purpose. Another alternative would be to just use an unordered list or
table and perhaps use something like a
bloom filter to check whether a
location has already been accessed as most accesses are likely to either target
new locations or a recently used location. However, with k-CAS, it would still
be necessary to sort the accesses later and, without some way to perform
efficient lookups, worst case performance would be quadratic O(n²).
For the purpose of implementing a transaction log, rather than just for the purpose of sorting a list of operations, a splay tree also offers further advantages. A splay tree works a bit like a cache, making accesses to recently accessed elements faster. In particular, the pattern where a location is first read and then written
let decr_if_positive ~xt x =
if Xt.get ~xt x > 0 then
Xt.decr ~xt xis optimised by the splay tree. The first access brings the location to the root of the tree. The second access is then guaranteed constant time.
Using a splay tree as the transaction log also allows the user to optimise transactions similarly to avoiding the cost of the linearithmic sorting step. A transaction over an array of locations, for example, can be performed in linear time simply by making sure that the locations are accessed in order.
Of course, none of this means that a splay tree is necessarily the best or the most efficient data structure to implement a transaction log. Far from it. But in OCaml, with fast memory allocations, it is probably difficult to do much better without additional runtime or compiler support.
Take a Number
One nice thing about transactions is that the user no longer has to write loops
to perform them. With a primitive (multi-word) CAS one needs to have some
strategy to deal with failures. If an operation fails, due to another CPU core
having won the race to modify some location, it is generally not a good idea to
just immediately retry. The problem with that is that there might be multiple
CPU cores trying to access the same locations in parallel. Everyone always
retrying at the same time potentially leads to quadratic O(n²) bus traffic to
synchronise shared memory as every round of retries generates O(n) amount of
bus traffic.
Suppose multiple CPU cores are all simultaneously running the following naïve lock-free algorithm to increment an atomic location:
let rec naive_incr atomic =
let n = Atomic.get atomic in
if not (Atomic.compare_and_set atomic n (n + 1)) then
naive_incr atomicAll CPU cores read the value of the location and then attempt a compare-and-set. Only one of them can succeed on each round of attempts. But one might still reasonably ask: what makes this so expensive? Well, the problem comes from the way shared memory works. Basically, when a CPU core reads a location, the location will be stored in the cache of that core and will be marked as "shared" in the caches of all CPUs that have also read that location. On the other hand, when a CPU core writes to a location, the location will be marked as "modified" in the cache of that core and as "invalid" in the caches of all the other cores. Although a compare-and-set doesn't always logically write to memory, to ensure atomicity, the CPU acts as if it does. So, on each round through the algorithm, each core will, in turn, attempt to write to the location, which invalidates the location in the caches of all the other cores, and require them to read the location again. These invalidations and subsequent reads of the location tend to be very resource intensive.
In some lock-free algorithms it is possible to use auxiliary data structures to
deal with contention scalably,
but when the specifics of the use case are unknown, something more general is
needed. Assume that, instead of all the cores retrying at the same time, the
cores would somehow form a queue and attempt their operations one at a time.
Each successful increment would still mean that the next core to attempt
increment would have to expensively read the location, but since only one core
makes the attempt, the amount of bus traffic would be linear O(n).
A clever way to form a kind of queue is to use randomised exponential backoff. A random delay or backoff is applied before retrying:
let rec incr_with_backoff ?(backoff = Backoff.default) atomic =
let n = Atomic.get atomic in
if not (Atomic.compare_and_set atomic n (n + 1)) then
incr_with_backoff ~backoff:(Backoff.once backoff) atomicIf multiple parties are involved, this makes them retry in some random order. At first everyone retries relatively quickly and that can cause further failures. On each retry the maximum backoff is doubled, increasing the probability that retries are not performed at the same time. It might seem somewhat counterintuitive that waiting could improve performance, but this can greatly reduce the amount of synchronisation and improve performance.
The Kcas library already employed a backoff mechanism. Many operations used a backoff mechanism internally and allocated an object to hold the backoff configuration and state as the first thing. To reduce overheads and make the library more tunable, I redesigned the backoff mechanism to encode the configuration and state in a single integer so that no allocations are required. I also changed the operations to take the backoff as an optional argument so that users could potentially tune the backoff for specific cases, such as when a particular transaction should take priority and employ shorter backoffs, or the opposite.
Free From Obstructions
The new k-CAS algorithm was efficient, but it was limited to CAS operations that
always wrote to shared memory locations. Interestingly, a CAS operation can also
express a compare (CMP) operation — just use the same value as the
expected and desired value, Op.make_cas loc expected expected.
One might wonder; what is the use of read-only operations? It is actually common for the majority of accesses to data structures to be read-only and even read-write operations of data structures often involve read-only accesses of particular locations. As explained in the paper Nonblocking k-compare-single-swap, to safely modify a singly-linked list typically requires not only atomically updating a pointer, but also ensuring that other pointers remain unmodified.
The problem with using a read-write CAS to express a read-only CMP is that, due to the synchronisation requirements, writes to shared memory are much more expensive than reads. Writes to a single location cannot proceed in parallel. Multiple cores trying to "read" a location in memory using read-write CASes would basically cause similar expensive bus traffic, or cache line ping-pong, as with the previously described naïve increment operation — without even attempting to logically write to memory.
To address this problem I extended the new lock-free k-CAS algorithm to a brand new obstruction-free k-CAS-n-CMP algorithm that allows one to perform a combination of read-write CAS and read-only CMP operations. The extension to k-CAS-n-CMP is a rather trivial addition to the k-CAS algorithm. The gist of the k-CAS-n-CMP algorithm is to perform an additional step to validate all the read-only CMP accesses before committing the changes. This sort of validation step is a fairly common approach in non-blocking algorithms.
The obstruction-free k-CAS-n-CMP algorithm also retains the lock-free k-CAS algorithm as a subset. In cases where only CAS operations are performed, the k-CAS-n-CMP algorithm does the exact same thing as the k-CAS algorithm. This allows a transaction mechanism based on the k-CAS-n-CMP algorithm to easily switch to using only CAS operations to guarantee lock-free behavior. The difference between an obstruction-free and a lock-free algorithm is that a lock-free algorithm guarantees that at least one thread will be able to make progress. With the obstruction-free validation step it is possible for two or more threads to enter a livelock situation, where they repeatedly and indefinitely fail during the validation step. By switching to lock-free mode, after detecting a validation failure, it is possible to avoid such livelocks.
Giving Monads a Pass
The original transactional API to k-CAS actually used monadic combinators.
Gabriel Scherer suggested the alternative API based on passing a mutable
transaction log explicitly that we've already used in the examples. This has the
main advantage that such an API can be easily used with all the existing control
flow structures of OCaml, such as if then else and for to do as well as
higher-order functions like List.iter, that would need to be encoded with
combinators in the monadic API.
On the other hand, a monadic API provides a very strict abstraction barrier against misuse as it can keep users from accessing the transaction log directly. The transaction log itself is not thread safe and should not be accessed or reused after it has been consumed by the main k-CAS-n-CMP algorithm. Fortunately there is a way to make such misuse much more difficult as described in the paper Lazy Functional State Threads by employing higher-rank polymorphism. By adding a type variable to the type of the transaction log
type 'x tand requiring a transaction to be universally quantified
type 'a tx = {
tx : 'x. xt:'x t -> 'a;
}with respect to the transaction log, the type system prevents a transaction log from being reused:
# let futile x =
let log = ref None in
let tx ~xt =
match !log with
| None ->
log := Some xt;
raise Retry.Later
| Some xt ->
Xt.get ~xt x in
Xt.commit { tx }
Line 10, characters 17-19:
Error: This field value has type xt:'a Xt.t -> 'b which is less general than
'x. xt:'x Xt.t -> 'cIt is still possible to e.g. create a closure that refers to a transaction log after it has been consumed, but that requires effort from the programmer and should be unlikely to happen by accident.
The explicit transaction log passing API proved to work well and the original monadic transaction API was then later removed from the Kcas library to avoid duplicating effort.
Division of Labour
When was the last time you implemented a non-trivial data structure or algorithm from scratch? For most professionals the answer might be along the lines of "when I took my data structures course at the university" or "when I interviewed for the software engineering position at Big Co".
Kcas aims to be usable both
- for experts implementing correct and performant lock-free data structures, and
- for everyone gluing together programs using such data structures.
Implementing lock-free data structures, even with the help of k-CAS-n-CMP, is not something everyone should be doing every time they are writing concurrent programs. Instead programmers should be able to just reuse carefully constructed data structures.
As an example, consider the implementation of a least-recently-used (LRU) cache or a bounded associative map. A simple sequential approach to implement a LRU cache is to use a hash table and a doubly-linked list and keep track of the amount of space in the cache:
type ('k, 'v) cache =
{ space: int Loc.t;
table: ('k, 'k Dllist.node * 'v) Hashtbl.t;
order: 'k Dllist.t }On a cache lookup the doubly-linked list node corresponding to the accessed key is moved to the left end of the list:
let get_opt {table; order; _} key =
Hashtbl.find_opt table key
|> Option.map @@ fun (node, datum) ->
Dllist.move_l node order; datumOn a cache update, in case of overflow, the association corresponding to the node on the right end of the list is dropped:
let set {table; order; space; _} key datum =
let node =
match Hashtbl.find_opt table key with
| None ->
if 0 = Loc.update space (fun n -> max 0 (n-1))
then Dllist.take_opt_r order
|> Option.iter (Hashtbl.remove table);
Dllist.add_l key order
| Some (node, _) -> Dllist.move_l node order; node
in
Hashtbl.replace table key (node, datum)Sequential algorithms such as the above are so common that one does not even think about them. Unfortunately, in a concurrent setting the above doesn't work even if the individual operations on lists and hash tables were atomic.
As it happens, the individual operations used above are actually atomic, because
they come from the
kcas_data
package. The kcas_data package provides lock-free and parallelism safe
implementations of various data structures.
But how would one make the operations on a cache atomic as a whole? As explained by Maurice Herlihy in one of his talks on Transactional Memory adding locks to protect the atomicity of the operation is far from trivial.
Fortunately, rather than having to e.g. wrap the cache implementation behind a
mutex and make
another individually atomic yet uncomposable data structure, or having to learn
a completely different programming model and rewrite the cache implementation,
we can use the transactional programming model provided by the Kcas library and
the transactional data structures provided by the kcas_data package to
trivially convert the previous implementation to a lock-free composable
transactional data structure.
To make it so, we simply use transactional versions, *.Xt.*, of operations on
the data structures and explicitly pass a transaction log, ~xt, to the
operations. For the get_opt operation we end up with
let get_opt ~xt {table; order; _} key =
Hashtbl.Xt.find_opt ~xt table key
|> Option.map @@ fun (node, datum) ->
Dllist.Xt.move_l ~xt node order; datumand the set operation is just as easy to convert to a transactional version.
One way to think about transactions is that they give us back the ability to
compose programs such as the above. But, I digress, again.
It was not immediately clear whether Kcas would be efficient enough. A simple node based queue, for example, seemed to be significantly slower than an implementation of the Michael-Scott queue using atomics. How so? The reason is fundamentally very simple. Every shared memory location takes more words of memory, every update allocates more, and the transaction log also allocates memory. All the extra words of memory need to be written to by the CPU and this invariably takes some time and slows things down.
For the implementation of high-performance data structures it is important to offer ways, such as the ability to take advantage of the specifics of the transaction log, to help ensure good performance. A common lock-free algorithm design technique is to publish the desire to perform an operation so that other parties accessing the same data structure can help to complete the operation. With some care and ability to check whether a location has already been accessed within a transaction it is possible to implement such algorithms also with Kcas.
Using such low level lock-free techniques, it was possible to implement a queue using three stacks:
type 'a t = {
front : 'a list Loc.t;
middle : 'a list Loc.t;
back : 'a list Loc.t;
}The front stack is reversed so that, most of the time, to take an element from the queue simply requires popping the top element from the stack. Similarly to add an element to the queue just requires pushing the element to the top of the back stack. The difficult case is when the front becomes empty and it is necessary to move elements from the back to the front.
The third stack acts as a temporary location for publishing the intent to reverse it to the front of the queue. The operation to move the back stack to the middle can be done outside of the transaction, as long as the back and the middle have not yet been accessed within the transaction.
The three-stack queue turned out to perform well — better, for example, than some non-compositional lock-free queue implementations. While Kcas adds overhead, it also makes it easier to use more sophisticated data structures and algorithms. Use of the middle stack, for example, requires atomically updating multiple locations. With plain single-word atomics that is non-trivial.
Similar techniques also allowed the Hashtbl implementation to perform various
operations on the whole hash table in ways that avoid otherwise likely
starvation issues with large transactions.
Intermission
This concludes the first part of this two part post. In the next part we will continue our discussion on the development of Kcas, starting with the addition of a fundamentally new feature to Kcas which turns it into a proper STM implementation.
HideOBuilder on macOS — Tarides, Aug 02, 2023
Introduction
The CI team at Tarides provides critical infrastucture to support the OCaml community. At the heart of that infrastructure is providing a cluster of machines for running jobs. This blog post details how we improved our support for macOS and moved closer to our goal of supporting all Tier1 OCaml platforms.
In 2022, Patrick Ferris of Tarides, successfully implemented a macOS worker for OBuilder. The workers were added to opam-repo-ci and OCaml CI, and this work was presented at the OC…
Introduction
The CI team at Tarides provides critical infrastucture to support the OCaml community. At the heart of that infrastructure is providing a cluster of machines for running jobs. This blog post details how we improved our support for macOS and moved closer to our goal of supporting all Tier1 OCaml platforms.
In 2022, Patrick Ferris of Tarides, successfully implemented a macOS worker for OBuilder. The workers were added to opam-repo-ci and OCaml CI, and this work was presented at the OCaml workshop in 2022 (video).
Since then, I took over the day-to-day responsibility. This work builds upon those foundations to achieve a greater throughput of jobs on the existing Apple hardware. Originally, we launched macOS support using rsync for snapshots and user accounts for sandboxing and process isolation. At the time, we identified that this architecture was likely to be relatively slow1 given the overhead of using rsync over native file system snapshots.
This post describes how we switched the snapshots over to use ZFS, which has improved the I/O throughput, leading to more jobs built per hour. It also removed our use of MacFUSE, both simplifying the setup and further improving the I/O throughput.
OBuilder
The OBuilder library is the core of Tarides' CI Workers 2. OCaml CI, opam-repo-ci, OCurrent Deployer, OCaml Docs CI, and the Base Image Builder all generate jobs which need to be executed by OBuilder across a range of platforms. A central scheduler accepts job submissions and passes them off to individual workers running on physical servers. These jobs are described in a build script similar to a Dockerfile.
OBuilder takes the build scripts and performs its steps in a sandboxed environment. After each step, OBuilder uses the snapshot feature of the filesystem (ZFS or Btrfs) to store the state of the build. There is also an rsync backend that copies the build state. On Linux, it uses runc to sandbox the build steps, but any system that can run a command safely in a chroot could be used. Repeating a build will reuse the cached results.
It is worth briefly expanding upon this description to understand the typical steps OBuilder takes. Upon receiving a job, OBuilder loads the base image as the starting point for the build process. A base image contains an opam switch with an OCaml compiler installed and a Git clone of opam-repository. These base images are built periodically into Docker images using the Base Image Builder and published to Docker Hub. Steps within the job specification could install operating system packages and opam libraries before finally building the test package and executing any tests. A filesystem snapshot of the working folder is taken between each build step. These snapshots allow each step to be cached, if the same job is executed again or identical steps are shared between jobs. Additionally, the opam package download folder is shared between all jobs.
On Linux-based systems, the file system snapshots are performed by Btrfs and process isolation is performed via runc. A ZFS implementation of file system snapshots and a pseudo implementation using rsync are also available. Given sufficient system resources, tens or hundreds of jobs can be executed concurrently.
The macOS Challenges
macOS is a challenging system for OBuilder because there is no native container support. We must manually recreate the sandboxing needed for the build steps using user isolation. Furthermore, macOS operating system packages are installed via Homebrew, and the Homebrew installation folder is not relocatable. It is either /usr/local on Intel x86_64 or /opt/homebrew on Apple silicon (ARM64). The Homebrew documentation includes the warning Pick another prefix at your peril!, and the internet is littered with bug reports of those who have ignored this warning. For building OCaml, the per-user ~/.opam folder is relocatable by setting the environment variable OPAMROOT=/path; however, once set it cannot be changed, as the full path is embedded in objects built.
We need a sandbox that includes the user's home directory and the Homebrew folder.
Initial Solution
The initial macOS solution used dummy users for the base images, user isolation for the sandbox, a FUSE file system driver to redirect the Homebrew installation, and rsync to create file system snapshots.
For each step, OBuilder used rsync to copy the required snapshot from the store to the user’s home directory. The FUSE file system driver redirected filesystem access to /usr/local to the user’s home directory. This allowed the state of the Homebrew installation to be captured along with the opam switch held within the home directory. Once the build step was complete, rsync copied the current state back to the OBuilder store. The base images exist in dummy users' home directories, which are copied to the active user when needed.
The implementation was reliable but was hampered by I/O bottlenecks, and the lack of opam caching quickly hit GitHub's download rate limit.
A New Implementation
OBuilder already supported ZFS, which could be used on macOS through the OpenZFS on OS X project. The ZFS and other store implementations hold a single working directory as the root for the runc container. On macOS, we need the sandbox to contain both the user’s home directory and the Homebrew installation, but these locations need to be in place within the file system. This was achieved by adding two ZFS subvolumes mounted on these paths.
| ZFS Volume | Mount point | Usage |
|---|---|---|
| obuilder/result/ |
/Volumes/obuilder/result/ |
Job log |
| obuilder/result/ |
/Users/mac1000 | User’s home directory |
| obuilder/result/ |
/opt/homebrew or /usr/local | Homebrew installation |
The ZFS implementation was extended to work recursively on the result folder, thereby including the subvolumes in the snapshot and clone operations. The sandbox is passed the ZFS root path and can mount the subvolumes to the appropriate mount points within the file system. The build step is then executed as a local user.
The ZFS store and OBuilder job specification included support to cache arbitrary folders. The sandbox was updated to use this feature to cache both the opam and the Homebrew download folders.
To create the initial base image, empty folders are mounted on the user home directory and Homebrew folder, then a shell script installs opam, OCaml, and a Git clone of the opam repository. When a base image is initially needed, the ZFS volume can be cloned as the basis of the first step. This replaces the Docker base images with OCaml and opam installed in them used by the Linux OBuilder implementation.
| ZFS Volumes for macOS Homebrew Base Image for OCaml 4.14 |
|---|
| obuilder/base-image/macos-homebrew-ocaml-4.14 |
| obuilder/base-image/macos-homebrew-ocaml-4.14/brew |
| obuilder/base-image/macos-homebrew-ocaml-4.14/home |
Performance Improvements
The rsync store was written for portability, not efficiency, and copying the files between each step quickly becomes the bottleneck. ZFS significantly improves efficiency through native snapshots and mounting the data at the appropriate point within the file system. However, this is not without cost, as unmounting a file system causes the disk-write cache to be flushed.
The ZFS store keeps all of the cache steps mounted. With a large cache disk (>100GB), the store could reach several thousand result steps. As the number of mounted volumes increases, macOS’s disk arbitration service takes exponentially longer to mount and unmount the file systems. Initially, the number of cache steps was artificially limited to keep the mount/unmount times within acceptable limits. Later, the ZFS store was updated to unmount unused volumes between each step.
The rsync store did not support caching of the opam downloads folder. This quickly led us to hit the download rate limits imposed by GitHub. Homebrew is also hosted on GitHub; therefore, these steps were also impacted. The list of folders shared between jobs is part of the job specification and was already passed to the sandbox, but it was not implemented. The job specification was updated to include the Homebrew downloads folder, and the shared cache folders were mounted within the sandbox.
Throughput has been improved by approximately fourfold. The rsync backend gave a typical performance of four jobs per hour. With ZFS, we see jobs rates of typically 16 jobs per hour. The best recorded rate with ZFS is over 100 jobs per hour!
Multi-User Considerations
The rsync and ZFS implementations are limited to running one job simultaneously, limiting the throughput of jobs on macOS. It would be ideal if the implementation could be extended to support concurrent jobs; however, with user isolation, it is unclear how this could be achieved, as the full path of the OCaml installation is included in numerous binary files within the ~/.opam directory. Thus, opam installed in /Users/foo/.opam could not be mounted as /Users/bar/.opam. The other issue with supporting multiuser is that Homebrew is not designed to be used by multiple Unix users. A given Homebrew installation is only meant to be used by a single non-root user.
Summary
With this work adding macOS support to OBuilder using ZFS, the cluster provides workers for macOS on both x86_64 and ARM64. This capability is available to all CI systems managed by Tarides. Initial support has been added to opam-repo-ci to provide builds for the opam repository, allowing us to check packages build on macOS. We have also added support to OCaml-CI to provide builds for GitHub and GitLab hosted projects, and there is work in progress to provide macOS builds for testing OCaml's Multicore support. MacOS builds are an important piece of our goal to provide builds on all Tier 1 OCaml platforms. We hope you find it useful too.
All the code is open source and available on github.com/ocurrent.
- As compared to other workers where native snapshots are available, such as BRTRS on Linux.↩
- In software development, a "Continuous Integration (CI) worker" is a computing resource responsible for automating the process of building, testing, and deploying code changes in Continuous Integration systems.↩
OCaml in Space - Welcome SpaceOS! — Tarides, Jul 31, 2023
Our mission is to build sustainable and secure software infrastructure that will not only work for decades but also positively impact the world. This includes our work on essential open-source libraries and tooling in the OCaml space, but also extends to include cutting-edge innovation through MirageOS technologies. We are investigating mission-critical IoT use cases: one of which is facilitating the deployment of secure high-performance applications in space to help data scientists write models…
Read more...Our mission is to build sustainable and secure software infrastructure that will not only work for decades but also positively impact the world. This includes our work on essential open-source libraries and tooling in the OCaml space, but also extends to include cutting-edge innovation through MirageOS technologies. We are investigating mission-critical IoT use cases: one of which is facilitating the deployment of secure high-performance applications in space to help data scientists write models that run on satellite-generated data. In this post, we present our solution that does just that: SpaceOS.
The satellite industry is transforming! As a result, an exciting commercial space industry is emerging – one that industry professionals are increasingly referring to as ‘NewSpace’.
The NewSpace Opportunity
For those unfamiliar with NewSpace, here is a brief overview. Historically, satellites have been owned and operated by large and powerful companies that could afford the costs inherent in their design, launch, and operation. In addition to their high cost of production, this generation of satellites rarely changes their software/hardware configuration to avoid operational risk, and consequently operates in the same way a decade after its launch.
The high cost and lack of software flexibility have made it difficult for smaller companies to enter the market, disincentivising the development of technologies that require the capabilities of satellites. A timely and broad example with many use cases is earth observation, including monitoring volcanic activity, forest fires, agriculture, and oil spill detection.
Fast forward to today. New technologies – resulting in smaller satellites and significant reductions in launch costs – as well as new business models such as shared satellites and satellites as a service, now make it possible for many smaller companies to benefit from satellite capabilities. More satellites have been launched into space in the last two years than the fifty years before. Welcome to NewSpace, where multi-user and multi-mission satellites are becoming the norm!
NewSpace Needs New Software
NewSpace requires new software capabilities. The traditional and outdated practice of launching satellites and leaving them untouched for 15-20 years is no longer effective.
NewSpace requires the ability to run software from multiple users on the same satellites whilst maintaining software isolation (between applications and data of different users), as well as complete separation from the flight system software. Software must also be easy to update to allow for software innovation (for instance, to use a new machine learning inference algorithm) or to enable the new concept of usage-based models (where users pay for time spent or resources used). Existing platforms are not able to satisfy these new software requirements.
Many satellite operators either develop their own custom software stack (including their own operating system) or use complex Cloud-native software, such as Docker and Kubernetes, to manage multi-user and multi-mission needs. Cloud-native technologies are suboptimal in this context and, in particular, are inefficient for resource-constrained onboard satellite computing systems. There is a need for an alternative solution that is secure, efficient and easy to use.
Welcome to SpaceOS!
SpaceOS is an operating system that is secure by design, providing complete isolation between user software paired with effortless software updates.
Multipurpose: Currently, there is no standard OS for satellites. Launching your software on a satellite platform requires you to write your own software based on different satellite and satellite service provider specifications. SpaceOS ensures compatibility across multiple satellites and service providers, ensuring you only need to write your software once.
Flexible: With SpaceOS, software updates are easy. Users can choose from powerful containerisation options, or opt to run on bare metal.
Compact: SpaceOS is small. A recent demonstration showcased that for an earth observation application, SpaceOS was 20 times smaller when compared to the classic Kubernetes approach, also requiring less memory and processing power.
Secure: SpaceOS is built on stable and safe programming logic (read on for details about the memory safety of OCaml) and MirageOS unikernel technology. The MirageOS Bitcoin Pinata is an example of a very successful, efficient, and transparent bug bounty program. Over 3 years the pinata was exposed to 150,000 hack attacks without success. Since MirageOS-style unikernels also power the SpaceOS solution, this test is a good indication of its cybersecurity strength.
How is This Huge Leap in OS Technology Possible?
Adapting to rapid development in any field often necessitates a paradigm shift. The order-of-magnitude improvements that SpaceOS provides over existing alternatives are only made possible due to fundamental changes in the underlying technology.
How can a software platform provide the powerful OS environment required for NewSpace? To explain, one must understand what unikernels are and how the design of a programming language directly impacts its cybersecurity vulnerability.
Unikernels: A Shift in OS Philosophy
Let us talk about how operating systems generally work. Most operating systems have been built with the aim of running on lots of different kinds of hardware, and supporting lots of different kinds of applications (many of which don’t exist yet when the OS is released and installed). This means that the operating system (such as Windows, Linux, macOS etc.) is optimised for broad compatibility, and is designed and built to provide a compelling platform for any application the user might need. This could include printer drivers, Bluetooth protocols, graphics card support, file system management, a range of network protocols, or user-space components such as systemd, ssh, logging systems… the list goes on.
In theory, the standard OS can theoretically service any number of applications. In practice, support for a wide range of applications that only “might” be used commonly leads to a large, resource-intensive OS vulnerable to cyber attack. Typically, any one application only requires a subset of the complete OS, and all of that extra functionality results in wasted resources and increased risk.
SpaceOS uses a different approach based on unikernel technology, and instead of being a general-purpose OS for any application, it is specialised for one unique application. In the build phase, SpaceOS analyses the application to determine the requirements for runtime. For example, if the application doesn’t require Bluetooth or a sound driver, these functionalities will not be included in the OS. The OS creates a highly specialised, efficient, and compact executable with a significantly smaller attack surface, specifically designed for its single use case.
This kind of unikernel technology is not yet widely used commercially, but recent examples of mission-critical applications include the CyberChaff joint project between the US Department of Defense (DOD) and Galois, and the NetHSM security module from Tarides partners, Nitrokey.
OCaml: Memory Safety by Design
SpaceOS has a second “secret” to add to the mix: it uses a memory-safe programming language called OCaml. The Cybersecurity and Infrastructure Security Agency (CISA) published a report emphasising the importance of Secure-By-Design principles as mitigation against cyber intrusions. Some widely used languages (such as C or C++) are not memory safe and, therefore, vulnerable by design. With memory-related attacks being the most common cyber attack, forming 70% of all zero-day attacks, the NSA (USA National Security Agency) also recommends using memory-safe languages.
This is why we have chosen OCaml for SpaceOS. OCaml is purposefully designed and developed with safety and performance in mind, and therefore we can confidently say that SpaceOS is “secure by design”. Read more about how OCaml can protect you against zero-day attacks.
Conclusion
SpaceOS and the underlying “secure by design” unikernel technology is a powerful and innovative new technology for in-space IoT and edge computing (with many other potential applications for mission-critical IoT use cases). By combining the performance and safety of OCaml with the specialisation and flexibility of unikernels, we aim to revolutionise the capabilities of NewSpace.
No other alternative offers similar capabilities today, which explains the very strong interest and many partnership discussions we are having with companies and organisations including such as Thales TAS, ESA, CNES, Infinite Orbits, Singapore Space Agency, OHB, Eutelsat, D-Orbit, and more.
Stay tuned to hear how SpaceOS will become the new global standard for NewSpace satellites and get in touch if you have any questions.
HideVariations on Weihrauch degrees (CiE 2023) — Andrej Bauer, Jul 27, 2023
I gave a talk “Variations on Weihrauch degrees” at Computability in Europe 2023, which took place in Tbilisi, Georgia. The talk was a remote one, unfortunately. I spoke about generalizations of Weihrauch degrees, a largely unexplored territory that seems to offer many opportunities to explore new directions of research. I am unlikely to pursue them myself, but will gladly talk with anyone who is interested in doing so.
Slides: CiE-2023-slides.pdf.
Reflections on the MirageOS Retreat in Morocco — Tarides, Jul 27, 2023
Introduction
Since we are a hybrid remote and distributed company, everyone at Tarides knows first-hand how important in-person retreats are for collaborating on software development. They give us a chance to focus more deeply on our work, collaborate closely, and learn from one another. We are particularly enthusiastic about the MirageOS retreats, which are organised by @hannesm from Robur and happen once to twice a year. These retreats bring together OCaml programmers and MirageOS enthusiasts …
Read more...Introduction
Since we are a hybrid remote and distributed company, everyone at Tarides knows first-hand how important in-person retreats are for collaborating on software development. They give us a chance to focus more deeply on our work, collaborate closely, and learn from one another. We are particularly enthusiastic about the MirageOS retreats, which are organised by @hannesm from Robur and happen once to twice a year. These retreats bring together OCaml programmers and MirageOS enthusiasts from all over the world to share ideas and work on projects.
For those unacquainted with it, MirageOS is a library operating system that lets users create 'unikernels' – light-weight, single-purpose machine images designed for secure, efficient, high-performance applications. MirageOS unikernels are written in OCaml, which is a functional, semantically-rich, and type-safe programming language.
This blog post offers a glimpse into our journey to the recent MirageOS retreat, which took us to Morocco. We will share our most memorable experiences from the retreat - the personal stories, the community bonding, the projects we worked on, and the things we learned. So, buckle up and join us as we reminisce on a journey of technical exploration and personal growth under the Moroccan sky.
The Journey to Morocco
Our experience of the MirageOS retreat was as much about the journey as it was about the destination. Some of us started our trip with a train ride to La Feria in Seville. It's a big spring festival in Spain that we were excited to experience. From there, we headed to Cadiz, another city in Spain known for its history and food.
Our final destination was Marrakech, Morocco. We stayed at a traditional Moroccan house called a riad, named the Queen of the Medina. The owner of the riad was very welcoming, and the house was comfortable and filled with local art. During our stay, we shared rooms and meals, growing closer to the rest of the community.
Right outside our riad was the famous Jemaa el-Fnaa square. It's a busy marketplace and a UNESCO World Heritage site, filled with music, food stalls, and plenty of action – especially in the evenings.
The journey to Morocco and the experiences we had along the way helped set the stage for a productive and enjoyable retreat.
The MirageOS Retreat Experiences
At the heart of the retreat was the daily 'circle'. Each day, we gathered together to share our experiences and discuss what we had been working on. These discussions provided insights into the different projects, and it was inspiring to hear about the progress that each person was making, often with the help of other participants at the retreat.
One highlight of the retreat was the night-time presentations. These covered various subjects, and not all were directly related to OCaml or MirageOS. The diversity of topics always sparked interesting conversations and created opportunities for us to learn from each other.
Throughout the retreat, a topic that came up often was how to increase the adoption of MirageOS. This spurred a lot of creative thinking, as we brainstormed new ways to promote the wider use of MirageOS.
And of course, we also had the opportunity to work on personal projects. Two of us, for instance, added the Git server commands to the ocaml-git library. Another project played music from a bare-metal Raspberry Pi 4!
But the retreat wasn't all work. We also found time for fun and relaxation. One memorable activity was the contact improvisation dance accompanied by live music, in which several retreat participants took part. After the week-long retreat ended, some of us stayed in Morocco to visit the Atlas Mountains, climb Jbel Toubkal, and go surfing in Imsouane.
Projects and Collaborations
During the retreat, we split into small groups of one or two engineers to work on different projects. The projects let us explore different aspects of Mirage that we found interesting and test the boundaries of what Mirage can do. Some of our projects included:
MIDI over Bare-Metal Raspberry Pi
Contributors: @pitag-ha, @Engil
We set out to explore the capabilities of a Raspberry Pi (RPi) in handling MIDI signals. We had a host of adapters at our disposal, including a GPIO board with MIDI DIN plugs and an adapter that could transform MIDI DIN to USB. Our colleague @Engil, who was one of the two main people working on this project, brought a synthesiser, enabling us to establish a direct connection to the GPIO board of the RPi. Additionally, the DIN-USB cable allowed us to connect our computers to the RPi for debugging purposes, using a program called Midisnoop.
Our primary objective was to send MIDI output from the RPi, which proved to be a straightforward task. We made use of @Dinosaure's bare-metal RPi toolchain, Gibraltar, which already had UART write support for logging. Since MIDI operates on a serial protocol, we decided to send it over UART as well. We adjusted the baudrate, converted some music into MIDI bytes, and sent it to the UART. Thanks to the functionalities already present in Gibraltar, we managed to play the intro of "Mr Sandman"!
We also attempted to receive MIDI signals. After some troubleshooting and experiments, we concluded that the GPIO board's MIDI Out DIN connector was faulty. We confirmed our theory by installing Linux on the RPi and running a Python program for MIDI output provided by the GPIO board's provider, but to no avail. It's amusing to note that it took us a whole day to install Linux and run a single program, compared to the ease and speed of booting a bare-metal MirageOS unikernel 🤓.
We had envisioned implementing MIDI In support to create a "bare-metal OCaml drum machine." The idea was to convert incoming MIDI signals into drum samples, similar to how synthesisers operate. The intention was to load drum samples into the unikernel's memory and generate the corresponding drum sounds upon receiving a MIDI event.
In a bid to broaden our experimentation, we also wanted to explore how we could send audio from the unikernel to the host system. The solution involved writing music to the unikernel's stdout and piping the unikernel into an ALSA function, which then played the received music. Although this wasn't typical usage of a unikernel, it proved to be a really fun experiment.
This project served as a testament to the flexibility and creative applications of unikernels, and we're excited about the further possibilities that this experiment will inspire.
Adding Git Server Commands to the ocaml-git
Contributors: @panglesd, @Julow
The primary goal of our project was to create a unikernel that could act as a Git server. We needed several components in order to accomplish this, including an OCaml implementation of the SSH protocol and an OCaml implementation of the Git protocol. For the SSH protocol, everything we needed was implemented in awa-ssh, but for ocaml-git things were a bit more complicated.
ocaml-git implements the Git format and part of the protocol. It is also used as a backend for Irmin and for fetching data in a unikernel. However, the server side part of the protocol that we needed was missing. It had not been needed in ocaml-git use cases before.
Our main challenge was that programming in ocaml-git can be really hard! There were a lot of monads at the same time, as well as Higher Kinded Types. Abstractions were necessary to support all the use cases we wanted, which were to use it in a Unix program or in a unikernel, as an Irmin backend, and as a library by a unikernel. We also needed to decipher some slightly vague documentation for the Git protocol, so there was some trial and error and reverse engineering of Git going on.
We were lucky enough to get some great help from several people. @Dinosaure walked us through the code of ocaml-git and answered many of our questions about Git's protocol, whereas @reynir helped us write a unikernel and answered our questions about SSH.
We implemented the project in a series of steps, starting by writing a 'cat' SSH unikernel as a basis for our server. We then implemented a server-side fetch protocol called upload-pack. We needed to do a lot of iterations and experimentation before we got it right, as the protocol was full of hidden details. We were finally able to create a git-clone that was answered by our server. It was just in time as well, as it was the last night of the retreat!
The next steps would be to implement the missing features like shallow clones for upload-pack, implement the server-side of push which is called receive-pack, and integrate all of this into a unikernel! If you'd like to help or just check out our project, you can look at the PR on GitHub.
Exploring Solo5 and Multicore
Contributors: @haesbaert, @fabbing
We were experimenting with Solo5 and Multicore. @haesbaert was trying to figure out how Unikraft booted and what parts of SMP it already had, as well as understanding what people expect from something like Unikraft. This involved checking the reservations and so on. Together with @kit-ty-kate, we tried to fix halting on Google Compute for Mirage, which involved diving into OpenBSD to see how they managed halting. After a lot of investigation, it seemed that in order to fix halting, we would need a proper ACPI implementation and some minor table parsing to achieve proper shutdown. @haesbaert also collaborated with Hannesm to fix an Eio bug in FreeBSD.
@fabbing was also working with @Dinosaure to learn about Solo5 and how to get multiple CPUs running. While they were working on Solo5 together, @Dinosaure went through and updated the Solo5 documentation.
OCaml Splashscreen
Contributors: @MisterDA
We started by wanting to explore DNS over HTTPS with MirageOS, and we managed to deploy a DNS server locally! However, with all of the exciting things going on all around us, we got distracted and started to work on smaller projects. We learned about generating OCaml bindings to C libraries with ctypes and started to expand the coverage of ocaml-posix. We set an informal goal to write a binding for FUSE with ctypes, which is still a work in progress. We also explored the steps involved with building MirageOS and OCaml on macOS, and found and fixed a couple of bugs.
We then started on a really fun project! It was all about splashscreens, or the windows that are shown when a program starts. We based it on the first chronophotography of a camel walking. @MisterDA extracted the camel using GIMP and turned it into a computer animation, displayed with the OCaml binding to SDL2. We then added a futuristic soundtrack, composed by @Engil, before being ready to present the OCamlWalk project.
It also acts as a wrapper around ocamlrun that you can use to launch OCaml bytecode executables. The camel walks, and OCaml runs!
Conclusion
The retreat was a great opportunity to meet other developers who are enthusiastic about MirageOS. We had some great discussions and brainstorming sessions, sharing ideas and insights with each other. Morocco provided an amazing setting for the retreat, with beautiful nature and historic cultural landmarks.
We're happy to be part of a vibrant community with a lot of passionate people, and we're already looking forward to the next opportunity to get together!
HideIf you're interested in exploring how to use Mirage to build highly-secure unikernels, for commercial uses, or even as a side project, do reach out to us. We'll be happy to help!
opam 2.2.0 alpha2 release — OCaml Platform (Raja Boujbel - OCamlPro, Kate Deplaix - Tarides), Jul 26, 2023
Feedback on this post is welcomed on Discuss!
We are happy to announce the second alpha release of opam 2.2.0. It contains some fixes and a new feature for Windows. You can view the full list in the release note.
This version is an alpha, we invite users to test it to spot previously unnoticed bugs to head towards the stable release.
Windows Support
The first alpha came with native Windows compatibility. This second alpha comes with a more simple init for Windows: we no longer rely on an alr…
Read more...Feedback on this post is welcomed on Discuss!
We are happy to announce the second alpha release of opam 2.2.0. It contains some fixes and a new feature for Windows. You can view the full list in the release note.
This version is an alpha, we invite users to test it to spot previously unnoticed bugs to head towards the stable release.
Windows Support
The first alpha came with native Windows compatibility. This second alpha comes with a more simple init for Windows: we no longer rely on an already present Cygwin UNIX-like environment for Windows as a compatibility layer. During initialisation, opam now proposes to embed its own fully managed Cygwin install.
The main opam-repository Windows compliance is still a work in progress, we recommend to use existing compatible repository (originally from @fdopen) and 32/64 bit mingw-w64 packages (by @dra27).
How to Test opam on Windows
This alpha requires a preexisting Cygwin installation for compiling opam.
- Check that you have all dependencies installed:
autoconf,make,patch,curl- MinGW compilers:
mingw64-x86_64-gcc-g++,mingw64-i686-gcc-g++ - Or if you want to use the MSVC port of OCaml, you'll need to install Visual Studio or Visual Studio Build Tools
- Download & extract the opam archive
- In the directory launch
make cold - A coffee later, you now have an opam executable!
- Start your preferred Windows terminal (
cmdorPowerShell), and initialise opam with the Windows sunset repository:opam init git+https://github.com/ocaml-opam/opam-repository-mingw
From here, you can try to install the sunset repository packages. If you find any bugs, please submit an issue. It will help opam-repository maintainers to add Windows repository packages into the main repository.
Hint: if you use the MinGW compiler, don't forget to add to your
PATHthe path tolibcdlls (usuallyC:\cygwin64\usr\x86_64-w64-mingw32\sys-root\mingw\bin). Or compile opam withmake cold CONFIGURE_ARGS=--with-private-runtime, and if you change opam location, don't forget to copyOpam.Runtime.amd64(orOpam.Runtime.i386) with it.
Updates & fixes
- opam var have now a more informative error message in case of package variable
- opam lint: update Error 29 on package variables on filters to check also
conflicts:field - opam admin lint: clean output when called not from a terminal
- configure: error if no complementary compiler is found on Windows
Try it!
In case you plan a possible rollback, you may want to first backup your
~/.opam directory.
The upgrade instructions are unchanged:
Either from binaries: run
bash -c "sh <(curl -fsSL https://raw.githubusercontent.com/ocaml/opam/master/shell/install.sh) --version 2.2.0~alpha2"or download manually from the Github "Releases" page to your PATH.
Or from source, manually: see the instructions in the README.
You should then run:
opam init --reinit -niPlease report any issues to the bug-tracker.
Thanks for trying this new release out, and we hope you will enjoy the new features!
HideSandmark: Boosting Multicore Projects with Performance Benchmarking — Tarides, Jul 19, 2023
Introduction
In the realm of software development, continuous improvement is paramount. When it comes to Multicore projects, the need for thorough benchmarking becomes even more critical. This is where Sandmark comes into play. Sandmark, developed for the OCaml programming language, has proven to be an invaluable tool for optimising performance and aiding in upstreaming efforts. In this blog post, we will explore the benefits of using Sandmark and its role in the development of Multicore project…
Read more...Introduction
In the realm of software development, continuous improvement is paramount. When it comes to Multicore projects, the need for thorough benchmarking becomes even more critical. This is where Sandmark comes into play. Sandmark, developed for the OCaml programming language, has proven to be an invaluable tool for optimising performance and aiding in upstreaming efforts. In this blog post, we will explore the benefits of using Sandmark and its role in the development of Multicore projects.
Enhancing Upstreaming Efforts
Sandmark has been extensively used in Multicore projects to assist with upstreaming. Its impact can be witnessed in the OCaml community, where it helped demonstrate that sequential programs running on OCaml 5 performed nearly as efficiently as those running on OCaml 4. For instance, the results achieved in the Multicore PR (pull request) merge were accomplished using Sandmark. Additionally, the findings presented in the ICFP'20 paper were all obtained through the utilisation of Sandmark. This tool has played a crucial role in showcasing the progress made tracking performance regressions in the OCaml compiler.
Ongoing Compiler Development
Even after the Multicore merge, Sandmark remains actively employed with a dashboard for the compiler development. Its significance is evident in the multitude of pull requests related to Sandmark in the OCaml repository. For example, consider the issue #11589, where an idle processing domain slows down major garbage collection (GC) cycles. The comparison of parallel benchmarks between the fix in the PR and the current development version of the compiler in the illustration shows the speedup comparisons. This highlights the continued reliance on Sandmark as a vital tool in the compiler development process.
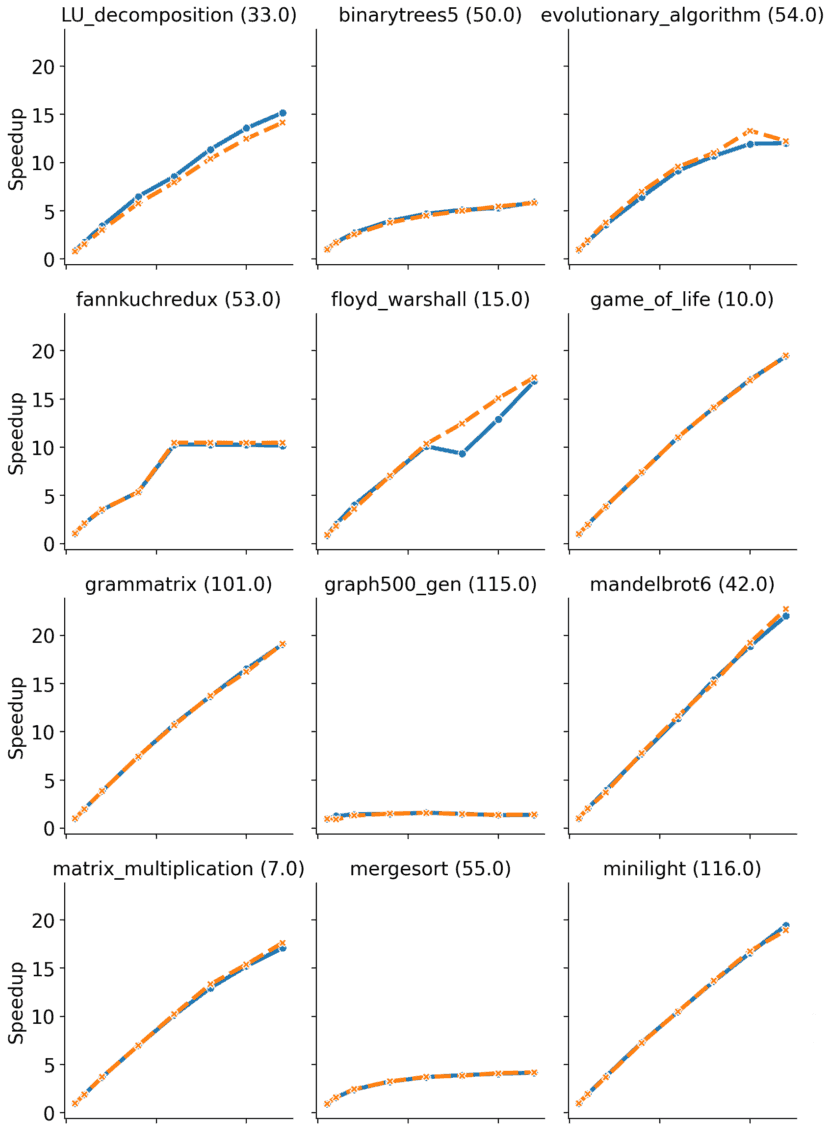
Nightly Benchmarking
One of the key aspects of Sandmark is its nightly benchmarking feature. Sandmark ensures that benchmarks are run regularly on diverse x86 servers, namely Turing (Intel Xeon Gold with 56 cores) and Navajo (AMD EPYC 7551 with 128 cores). This practice serves as a proactive measure to continuously identify and address performance regressions promptly. The nightly runs cover both sequential and parallel benchmarks, providing comprehensive insights into the program's behaviour under different scenarios for different inputs.
Sandmark Nightly Config
To simplify the process of requesting development branches for nightly benchmarking, Sandmark offers a convenient service called "Sandmark Nightly Config". This service streamlines simplifies the configuration setup for benchmarking, thereby reducing the steps required to initiate the benchmark runs. Compiler developers only need to provide their development branch URL for the configuration, and the nightly service will execute both the sequential and parallel benchmarks. By automating this process, developers can focus on their core tasks while still benefiting from gaining insights from the regular benchmark runsing insights.
Permalinks for Easy Sharing and Discussion
A remarkable feature of Sandmark is the provision of permalinks. These permalinks enable users to easily share benchmark results and engage in meaningful discussions. You can specify more than two development branches across dates, and even different hosts for comparison. This capability is a game-changer for collaborative development, as it facilitates efficient communication and fosters a deeper understanding of the pull request changes using the benchmarking outcomes. The permalinks in Sandmark allow for specific results to be referenced and examined in detail.
Importance of Perfstat Output
Sandmark offers perfstat output, which plays a vital role in accurately evaluating program performance. Modern machines exhibit varying raw running times due to their complex nature. However, “instructions retired” provide a more stable and reliable metric, especially when assessing the impact of compiler optimisations. This feature ensures that performance analysis is based on consistent and meaningful measurements.
Looking Towards the Future
Sandmark continues to evolve, with ongoing developments in the Multicore release. The efforts put into enhancing Sandmark reflect the commitment to improving Multicore programming in OCaml. As the OCaml community pushes the boundaries of Multicore development, Sandmark will undoubtedly play a crucial role in optimising performance, tracking regressions, and ensuring the stability of the language.
Conclusion
Sandmark has emerged as an indispensable tool for the OCaml community, particularly in the realm of Multicore projects. Its ability to benchmark performance, catch regressions, simplify configuration, and facilitate discussions through permalinks has greatly contributed to the OCaml compiler development process. The commitment to ongoing improvements and enhancements will help measure, monitor and track the compiler development as the OCaml language evolves. We encourage you to try the above services, and share any feedback or file new feature requests or GitHub issues for the Sandmark project.
References
- Sandmark. https://github.com/ocaml-bench/sandmark
- Multicore OCaml PR merge. https://github.com/ocaml/ocaml/pull/10831
- Retrofitting Parallelism onto OCaml. https://kcsrk.info/papers/retro-parallel_icfp_20.pdf
- Sandmark Dashboard. https://sandmark.tarides.com/
- Idle Domain Slows Down GC Cycles. https://github.com/ocaml/ocaml/issues/11589
- Sandmark-nightly-config. https://github.com/ocaml-bench/sandmark-nightly-config
Continuity principles and the KLST theorem — Andrej Bauer, Jul 18, 2023
On the occasion of Dieter Spreen's 75th birthday there will be a Festschrift in the Journal of Logic and Analysis. I have submitted a paper “Spreen spaces and the synthetic Kreisel-Lacombe-Shoenfield-Tseitin theorem”, available as a preprint arXiv:2307.07830, that develops a constructive account of Dieter's generalization of a famous theorem about continuity of computable functions. In this post I explain how the paper fits into the more general topic of continuity principles.
A continui…
Read more...On the occasion of Dieter Spreen's 75th birthday there will be a Festschrift in the Journal of Logic and Analysis. I have submitted a paper “Spreen spaces and the synthetic Kreisel-Lacombe-Shoenfield-Tseitin theorem”, available as a preprint arXiv:2307.07830, that develops a constructive account of Dieter's generalization of a famous theorem about continuity of computable functions. In this post I explain how the paper fits into the more general topic of continuity principles.
A continuity principle is a statement claiming that all functions from a given class are continuous. A silly example is the statement
Every map $f : X \to Y$ from a discrete space $X$ is continuous.
The dual
Every map $f : X \to Y$ to an indiscrete space $Y$ is continuous.
is equally silly, but these two demonstrate what we mean.
In order to find more interesting continuity principles, we have to look outside classical mathematics. A famous continuity principle was championed by Brouwer:
Brouwer's continuity principle: Every $f : \mathbb{N}^\mathbb{N}\to \mathbb{N}$ is continuous.
Here continuity is taken with respect to the discrete metric on $\mathbb{N}$ and the complete metric on $\mathbb{N}^\mathbb{N}$ defined by
$$\textstyle d(\alpha, \beta) = \lim_n 2^{-\min \lbrace k \in \mathbb{N} \,\mid\, k = n \lor \alpha_k \neq \beta_k\rbrace}.$$
The formula says that the distance between $\alpha$ and $\beta$ is $2^{-k}$ if $k \in \mathbb{N}$ is the least number such that $\alpha_k \neq \beta_k$. (The limit is there so that the definition works constructively as well.) Brouwer's continuity principle is valid in the Kleene-Vesley topos.
In the effective topos we have the following continuity principle:
KLST continuity principle: Every map $f : X \to Y$ from a complete separable metric space $X$ to a metric space $Y$ is continuous.
The letters K, L, S, and T are the initials of Georg Kreisel, Daniel Lacombe, Joseph R. Shoenfield, and Grigori Tseitin, who proved various variants of this theorem in the context of computability theory (the above version is closest to Tseitin's).
A third topos with good continuity principles is Johnstone's topological topos, see Section 5.4 of Davorin Lešnik's PhD dissertaton for details.
There is a systematic way of organizing such continuity principles with synthetic topology. Recall that in synthetic topology we start by axiomatizing an object $\Sigma \subseteq \Omega$ of “open truth values”, called a dominance, and define the intrinsic topology of $X$ to be the exponential $\Sigma^X$. This idea is based on an observation from traditional topology: the topology a space $X$ is in bijective correspondence with continuous maps $\mathcal{C}(X, \mathbb{S})$, where $\mathbb{S}$ is the Sierpinski space.
Say that a map $f : X \to Y$ is intrinsically continuous when the invese image map $f^\star$ maps intrinsically open sets to intrinsically open sets.
Intrinsic continuity principle: Every map $f : X \to Y$ is intrinsically continuous.
Proof. The inverse image $f^\star(U)$ of $U \in \Sigma^Y$ is $U \circ f \in \Sigma^X$. □
Given how trivial the proof is, we cannot expect to squeeze much from the intrinsic continuity principle. In classical mathematics the principle is trivial because there $\Sigma = \Omega$, so all intrinsic topologies are discrete.
But suppose we knew that the intrinsic topologies of $X$ and $Y$ were metrized, i.e., they coincided with metric topologies induces by some metrics $d_X : X \times X \to \mathbb{R}$ and $d_Y : Y \times Y \to \mathbb{R}$. Then the intrinsic continuity principle would imply that every map $f : X \to Y$ is continuous with respect to the metrics. But can this happen? In “Metric spaces in synthetic topology” by Davorin Lešnik and myself we showed that in the Kleene-Vesley topos the intrinsic topology of a complete separable metric space is indeed metrized. Consequently, we may factor Brouwer's continuity principles into two facts:
- Easy general fact: the intrinsic continuity principle.
- Hard specific fact: in the Kleene-Vesley topos the intrinsic topology of a complete separable metric space is metrized.
Can we similarly factor the KLST continuity principle? I give an affirmative answer in the submitted paper, by translating Dieter Spreen's “On Effective Topological Spaces” from computability theory and numbered sets to synthetic topology. What comes out is a new topological separation property:
Definition: A Spreen space is a topological space $(X, \mathcal{T})$ with the following separation property: if $x \in X$ is separated from an overt $T \subseteq X$ by an intrinsically open subset, then it is already separated from it by a $\mathcal{T}$-open subset.
Precisely, a Spreen space $(X, \mathcal{T})$ satisfies: if $x \in S \in \Sigma^X$ and $S$ is disjoint from an overt $T \subseteq X$, then there is an open $U \in \mathcal{T}$ such that $x \in U$ and $U \cap T = \emptyset$. The synthetic KLST states:
Synthetic KLST continuity principle: Every map from an overt Spreen space to a pointwise regular space is pointwise continuous.
The proof is short enough to be reproduced here. (I am skipping over some details, the important one being that we require open sets to be intrinsically open.)
Proof. Consider a map $f : X \to Y$ from an overt Spreen space $(X, \mathcal{T}_X)$ to a regular space $(Y, \mathcal{T}_Y)$. Given any $x \in X$ and $V \in \mathcal{T}_Y$ such that $f(x) \in V$, we seek $U \in \mathcal{T}_X$ such that $x \in U \subseteq f^\star(V)$. Because $Y$ is regular, there exist disjoint $W_1, W_2 \in \mathcal{T}_Y$ such that $x \in W_1 \subseteq V$ and $V \cup W_2 = Y$. The inverse image $f^\star(W_1)$ contains $x$ and is intrinsically open. It is also disjoint from $f^\star(W_2)$, which is overt because it is an intrinsically open subset of an overt space. As $X$ is a Spreen space, there exists $U \in \mathcal{T}_X$ such that $x \in U$ and $U \cap f{*}(W_2) = \emptyset$, from which $U \subseteq V$ follows. □
Are there any non-trivial Spreen spaces? In classical mathematics every Spreen space is discrete, so we have to look elsewhere. I show that they are plentiful in synthetic computability:
Theorem (synthetic computability): Countably based sober spaces are Spreen spaces.
Please consult the paper for the proof.
There is an emergent pattern here: take a theorem that holds under very special circumstances, for instance in a specific topos or in the presence of anti-classical axioms, and reformulate it so that it becomes generally true, has a simple proof, but in order to exhibit some interesting instances of the theorem, we have to work hard. What are some other examples of such theorems? I know of one, namely Lawvere's fixed point theorem. It took some effort to produce non-trivial examples of it, once again in synthetic computability, see On fixed-point theorems in synthetic computability.
HideRelease of Frama-C 27.1 (Cobalt) — Frama-C, Jul 18, 2023
OCaml-CI Renovated — Tarides, Jul 12, 2023
OCaml-CI started with the goal of making a better continuous build system for OCaml projects. When we began in 2019, the goals were clear: it should provide a zero-configuration experience for OCaml projects using opam and Dune, and it should use an incremental architecture to avoid expensive recomputation of builds. We're delighted to announce that we achieved these goals, and OCaml-CI is currently tracking over five hundred repositories and processing over a hundred thousand jobs daily. This i…
Read more...OCaml-CI started with the goal of making a better continuous build system for OCaml projects. When we began in 2019, the goals were clear: it should provide a zero-configuration experience for OCaml projects using opam and Dune, and it should use an incremental architecture to avoid expensive recomputation of builds. We're delighted to announce that we achieved these goals, and OCaml-CI is currently tracking over five hundred repositories and processing over a hundred thousand jobs daily. This is inspiring news to those already using OCaml-CI or developers looking for a CI solution for their OCaml project.
Throughout 2022, the Tarides CI team worked on rennovating OCaml-CI, focusing on improving the usability of the website, adding build history for branches, supporting new platforms, and launching experimental build support. We will cover all of those things in this blog post and hope you find them useful.
There is also a Discuss thread on CI Best Practices.
What is OCaml-CI?
Continuous Integration, or CI, performs a series of automated steps (or jobs), e.g., building and testing code. With it, developers can confidently and regularly integrate code into the central repository, relying on the automated CI system to detect and even fix problems early. This reduces production issues and leads to more robust and secure software. OCaml-CI is a Continuous Integration tool tailored for OCaml projects.
VALUE PROPOSITION OF OCAML-CI
- OCaml specific / no configuration
- Check on various platforms
- Linting like version bounds (upper and lower) and project metadata
- Incremental caching of builds
OCaml-CI adds value by targeting just OCaml projects that are written with the standard OCaml opam tooling for package management and Dune for building code. Because OCaml-CI targets a specific language, it does not require any configuration. Instead, it derives the necessary information from metadata in the opam and dune project files.
You never have to teach OCaml-CI about how to build OCaml!
Additionally, it can do clever things like linting your opam and dune files to check for common mistakes. It also checks the upper and lower version bounds of packages to see where they break. The biggest feature over most popular CI systems is that OCaml-CI can derive which hardware and operating system platforms a package supports and do builds across all of those platforms! That means if you want to check on Linux ARM64 or MacOS x86_64 or Linux s390x you can. All that comes with the added benefit of a caching strategy based on the incremental architecture, which won't repeat builds if not necessary.
Lets look at the new features that were added!
Redesigned UI Using Dream
When OCaml-CI came into existence in 2019, the focus was on providing a CI system based on an incremental architecture, so the user interface (UI) for OCaml-CI was kept simple. In 2022, the team worked with a designer to develop a consistent and contemporary theme to make the site look and feel like a modern website. We decided on a tech stack of Dream for the web framework, Tailwind CSS for styling, Tyxml for HTML generation, and Omigrate for database migrations. In the Design and Implementation section below, we cover the technical reasons for each choice.
Build History
Over the years, people consistently requested a provided build history. So we added a new history page to show the build history of a branch. This feature allows users to conveniently access and view historical builds in the context of similar builds of the branch. It shows every commit built by OCaml-CI, a summary of each build (including build status, the time at which the build started, and the running time of the build), and links to the commit's build page.
Live Updates
Pages now automatically update with new information as the build progresses! OCaml-CI adds build steps as they are created, so build statuses and runtimes all update as the build occurs.
In 2023, it’s unusual to have to refresh a page to update the information, so this is just us catching up!
Enriching Build Information
Timestamps and durations relevant to a build and each of its steps are now available. This feedback enables development teams to monitor the resources and time taken for their builds. It gives them what they need to identify bottlenecks and opportunities for faster build times.
Summary of a Repository's Health
When looking at an organisation's page, you will now see a summary of the default branch for each of your repos. Inspired by the UI of BuildKite, we hope to provide teams with a view of their builds that indicates the overall health of their repository. The chart of the last 15 builds makes anomalous builds easy to identify and investigate.
Mobile Version
OCaml-CI can now be conveniently used from a variety of devices. We have rewritten our pages to be responsive to mobile devices, choosing to pare information to the essentials for small screens. All the functionality of the main site is still available on the mobile version, so you can view logs or navigate to the GitHub PR for a build.
Experimental Builds
Experimental builds was a conceptual feature that was added to OCaml-CI in order to support build types that might not be stable or to introduce ones without breaking CI for all projects. Think of them as a kind of feature flag. Experimental builds are clearly labelled with (experimental) in the UI and will not report as failures if every other build passes. They let us boldly introduce new features like supporting new platforms or running new linting checks like package lower bounds.
macOS Experimental Builds
Using Experimental builds, we added support for macOS (both x86_64 and ARM64) to OCaml-CI. These builds will run on the latest two versions of OCaml on both architectures. Currently these are marked as experimental as we work towards making macOS builds more efficient. The path to supporting macOS has been a long one, starting back in late 2021, and has gone through two different implementations before reaching a stable state in early 2023. We have plans to publish a post going deeper into the technical details soon.
Design and Implementation
The story of why technical decisions are made on a project are often as interesting as the project itself. Here we will go through the thoughts about the technologies used and why.
As previously mentioned, we kicked off this work with a designer to help develop a consistent and contemporary theme for the site. They created a set of designs in Figma and also made example HTML pages using Tailwind CSS as a basis for the style sheets. Tailwind works by scanning HTML files, JavaScript components, and any other templates for class names to generate the corresponding styles and then write them to a static CSS file. There is an opam package tailwindcss that wraps this all up for us.
We decided to use Dream to replace OCaml-CI’s previous web layer based on Cohttp library for the following reasons:
Cohttpis a low-level library, so we had to hand-roll solutions to standard patterns that are generally provided by web frameworks. For example, we had to solve the CSRF problem consistently throughout our usage of forms and also construct our own solution to show flash messages. We understoodCohttpbut were interested in taking the opportunity to investigate other web frameworks in the OCaml landscape.- Inspired by frameworks like Sinatra (of Ruby fame) and Flask (from Python), our colleagues Rudi Grinberg and Thibaut Mattio (and others) had constructed a web framework called Opium. They suggested that we check out Dream.
- We were impressed by its elegance and polish. Dream has brilliant documentation, a ton of examples, and convenient functions and support for several standard patterns in web development. It also uses common OCaml types, so adding it to the project would be relatively straightforward. We immediately saw an opportunity to accomplish several things at once:
- Support a promising project by adopting it and contributing to it
- Create a non-trivial example of using Dream for the community
- Reduce complexity, modernise the UI, and make it easier to add new features
- Have a lot of fun!
As we began to work with Dream, we made the following choices:
- We chose to work with
TyXMLoverEmlso that we would have the guardrails of typed templates to help write correct HTML. This proved to be challenging in the beginning, but examples from the Opium project really helped our team figure out how to wieldTyXMLcorrectly. - Our team did not have any CSS expertise and, frankly, was a little bit at sea with how to implement some of our designer's suggested designs. Tailwind CSS really helped us out here. In particular, it made it possible for us to achieve responsiveness for different screens and light and dark modes.
- For our database layer, we chose to work with Omigrate, so we could introduce migrations and develop our information model with confidence.
We are working on improving the signup process and on introducing js_of_ocaml to replace the plain JavaScript that we previously introduced.
We’d Love Your Feedback
If you have an OCaml project hosted on GitHub or GitLab and would like to test drive OCaml-CI, please follow our getting-started guide. There are many popular projects already using OCaml-CI to improve their development, and we want to see your project too.
Please open an issue on https://github.com/ocurrent/ocaml-ci if you run into any problems or to suggest improvements and point out missing features. The Tarides team wants to support more OCaml platforms like Windows and FreeBSD so we can cover the full OCaml Tier 1 supported platforms and to continue improving the UI experience.
If you are curious about web development in OCaml, we recommend checking out Dream. Please use our code for reference and ask us questions or make suggestions for improvements. We are using the following technologies:
- current_incr - Self-adjusting computations
- OCurrent - a CI/CD pipeline OCaml eDSL
- Lwt - OCaml promises and concurrent I/O
- Tyxml - Typed HTML and SVG
- Capnp_rpc - OCaml Cap'n Proto RPC library
If we can learn and improve from your experience, we all win! Thank you!
Acknowledgements
The Tarides engineers that delivered this work are Étienne Marais, Ben Andrew, and Navin Keswani. We got much support and feedback from several of our Tarides colleagues and others in the OCaml community, and we are very grateful for all we learned from them. Special mention to Thibaut Mattio and Tim McGilchrist.
Making OCaml 5 Succeed for Developers and Organisations — Tarides, Jul 07, 2023
OCaml recently won the ACM SIGPLAN PL Software Award. The award recognises a software system that has had a significant impact on programming language implementation, research, and tools. It is especially notable that 4 out of the 14 named OCaml compiler developers are affiliated with Tarides: Anil, David, Jérôme, and me. In this post, I discuss the wider effort afoot at Tarides in order to make OCaml 5, the latest release of the OCaml programming language, succeed for developers. I should not…
Read more...OCaml recently won the ACM SIGPLAN PL Software Award. The award recognises a software system that has had a significant impact on programming language implementation, research, and tools. It is especially notable that 4 out of the 14 named OCaml compiler developers are affiliated with Tarides: Anil, David, Jérôme, and me. In this post, I discuss the wider effort afoot at Tarides in order to make OCaml 5, the latest release of the OCaml programming language, succeed for developers. I should note that I shall specifically focus on the new OCaml 5 features and omit important developments such as Tarides' work on the OCaml platform, which is discussed elsewhere.
I started hacking on OCaml when I joined Anil, Stephen, and Leo (who are also named in this award) at OCaml Labs in the University of Cambridge in 2014 to work on the Multicore OCaml project. The aim of the Multicore OCaml project was to add native support for concurrency and parallelism to the OCaml programming language. Multicore OCaml compiler was maintained as a fork of the OCaml compiler for many years before it merged with the mainline OCaml compiler in January 2022. After almost a year of work stabilising the features, OCaml 5.0 was finally released in December 2022, nearly 8 years after the first commit.
Has the Multicore OCaml project succeeded with the release of OCaml 5.0? The short answer is No. There is a long road to making OCaml 5 succeed for the developers. The goal of making OCaml 5 succeed for the developers is a two-step process:
- Help developers transition existing programs to OCaml 5
- Help developers take advantage of new concurrency and parallelism features in OCaml 5
Transitioning developers to OCaml 5
Even with the arrival of OCaml 5, most OCaml programs will remain sequential forever. It is important that developers can successfully transition their OCaml projects over to OCaml 5, even if they don't plan to use the new features. We have carefully designed OCaml 5 such that the breaking changes are minimized. In particular, we eschewed a potentially more scalable GC design since it broke the C FFI compatibility (see section 7 "Discussion" in the ICFP 2020 paper on the new GC design). The only breaking changes in OCaml 5 were the removal of the support for naked pointers and the unrelated removal of deprecated functions from the standard library. We released a dynamic detector for naked pointers to help developers find and remove naked pointers from their codebase.
Restoring Unimplemented Features
OCaml 5.0 was an experimental release with many features unimplemented. In particular, OCaml 5.0 only supported the x86 and ARM backends. With impressive efforts from the community, the OCaml maintainers have restored support for All Tier 1 platforms including RISC-V, s390x and Power. Tarides helped implement or review the support for all of these backends. Tarides engineers also restored other important features such as GC mark loop pre-fetching and frame-pointer support for x86 backend. These features will be in OCaml 5.1.
We have also been working on restoring other big-ticket items such as compaction and statmemprof which were not implemented for OCaml 5.0. In OCaml, compaction is the only time when the runtime releases memory allocated for the heap back to the operating system. Many long-running programs have an initialisation phase where they use a lot of memory followed by a steady state phase where they operate for a long time with less memory. It is a common practice to call Gc.compact() after the initialisation phase so that the steady-state memory usage of the program remains low. Without compaction, the steady state will also use as much memory as the peak memory usage. This problem was reported by the Infer team at Meta (who were otherwise able to switch to OCaml 5 easily, thanks to our focus on backwards compatibility).
Tarides engineers have opened a PR for restoring compaction. The compaction feature is slated to be restored in OCaml 5.2. We have also been working on restoring statmemprof, the statistical memory profiler for OCaml. We are hoping to have a PR ready for this in the coming weeks.
Fixing Performance Regressions
OCaml 5 is a major rewrite of the runtime system and comes with a completely new allocator and a garbage collector (GC). As a result, some large OCaml projects such as Frama-C, Pyre, EasyCrypt, and Infer have reported performance regressions. We have been steadily fixing these issues and have not encountered any serious challenges here. Many of the fixes have been incorporated into 5.1, and we expect more performance fixes to land in 5.2. The very fact that large open-source projects can build and test their code on OCaml 5 is itself a testament to our careful backwards-compatible implementation of OCaml 5.
Allocator Performance
A potential source of performance regressions is the allocator. OCaml 5 uses a new parallelism-aware allocator written from scratch and different from the well-performing best-fit allocator available in OCaml since 4.10. Major industrial users of OCaml have reported that best-fit performs better than the earlier first-fit and next-fit allocators. In our benchmarking efforts, we observed that OCaml 5 allocator performs as well as the best-fit allocator, as both allocators utilise size-segmented pages for the allocator. But our benchmarks are admittedly much smaller than industrial OCaml workloads.
In order to derisk the transition to OCaml 5, we have backported the OCaml 5 allocator to OCaml 4 compiler. The backported allocator helps industrial users run their workloads in OCaml 4 with only the allocator changed, which helps identify any regressions. We are working with one of our customers to test the backported allocator on their internal workloads. We hope to identify regressions that only show up at scale and fix them for everyone using OCaml 5.
Continuously Benchmarking Compiler Quality
One of the goals of OCaml 5 is that, for sequential programs, the performance of those programs running on OCaml 5 is no worse than running on OCaml 4. Not only can the developers compile and run their existing sequential code in OCaml 5, but the expectation is that the performance is also similar. To this end, we have been doing nightly benchmarking of compiled code using Sandmark, a benchmarking service consisting of real-world, open-source OCaml programs. Sandmark monitors a multitude of performance parameters related to running time, memory usage, and GC latency.
The benchmarks and the related repository of OCaml packages are constructed in such a way that they can build with both OCaml 4 and OCaml 5. This lets the compiler developers quickly identify any regressions that may be introduced in OCaml 5 with respect to the same code compiled under OCaml 4. Tarides is working to turn this into a GitHub bot that will make it easier for compiler developers to trigger benchmarking runs on development branches.
Better Observability
Another strong reason to move to OCaml 5 from OCaml 4, even if you plan to remain sequential, is the better observability tools that come with OCaml 5. Starting from OCaml 5, the compiler supports a new feature named runtime events, which brings deep introspection capabilities for OCaml programs running in production. Runtime events add a series of probes to the OCaml program that emits data at specific events. This lets the consumers of these events produce interesting insights into the running programs. For example, Olly is a consumer that reports GC statistics including latency distribution. Olly can also produce traces of OCaml program runs visualising the GC behaviours.
An important aspect of runtime events is that the cost of the probes in the fast path (when the probes are not emitting data) is so low that it is available for every OCaml 5 program. In particular, you do not need to recompile your programs with special options to enable event collection. Hence, every OCaml 5 program can be introspected at runtime for interesting events using Olly.
By default, the only probes available are to do with GC events. OCaml 5.1 also brings in support for Custom events, where the user can describe new probes. It unlocks exciting possibilities for application-specific introspection. For example, Meio is a command-line tool that lets the user monitor the status of their application built using Eio, a new concurrency library built using OCaml 5 features, at a per fiber (lightweight task) granularity.
Taking Advantage of OCaml 5 Features
We anticipate two kinds of developers to take advantage of OCaml 5:
- Those who want to use the new features in their existing code.
- Those who want to write new code using the new features.
There is an increase of positive noise around OCaml recently, which may attract new developers and organisations to OCaml. However, given the millions of lines of existing OCaml code, our aim is to tackle (1) first. We hope that the experience of helping (1) succeed will inform what we should focus on for (2).
Primitive Features
It is important at this point to note that OCaml 5 brings in distinct features for native concurrency and parallelism support in OCaml. For concurrency, OCaml 5 adds effect handlers, and for parallelism, it adds domains to the language. These features are spartan by design, and our aim is to build expressive libraries on top of these features, which will live outside the compiler distribution. The OCaml manual pages on effect handlers and parallelism give a good overview of these primitive features. I also discuss the approach we've taken in retrofitting concurrency to OCaml in the ICFP 2022 Keynote.
Concurrency Libraries
Eio -- I/O Library
For asynchronous, non-blocking I/O, OCaml 4 has two industrial-strength libraries such as Lwt and Async. These libraries simulate concurrency using a monad. They are both very successful, and OCaml code that does asynchronous I/O uses one of these libraries. These libraries do have some downsides in that, due to the use of a monad, they don't produce useful backtraces, and OCaml's built-in exceptions cannot be used. The separation of synchronous and asynchronous code (function colours) and the lack of easy-to-use, higher-kinded polymorphism in OCaml means that one ends up with two versions of useful functions: one for monadic code and another for non-monadic code. This leads to code duplication such as the need to have a separate Lwt's list module. These libraries can continue to be used in OCaml 5, but given that these libraries are not parallelism-safe, one cannot write parallel code that takes advantage of them out of the box.
Eio is a new direct-style I/O library built using effect handlers. It avoids function colouring by using native stacks provided by effect handlers, unlike Lwt and Async which simulate it using a monad. Thanks to this, Eio produces faster code, supports built-in exceptions, produces good backtraces, and avoids code duplication. Eio also is built to be parallelism-safe. Eio provides a generic cross-platform API that can utilise optimised backends on different platforms such as io_uring on Linux.
One particular aspect that I would like to highlight is that Eio provides bridges for Async and Lwt so that existing code can be incrementally translated to Eio. This aspect is crucial for adoption, as we believe that it is impractical to translate a large Lwt or Async codebase over to Eio in one go. Tarides is currently working towards the goal of Eio 1.0, which we expect to be released by Q3 2023. If you are interested in using Eio, Tarides engineers are running a hands-on tutorial on porting Lwt applications over to Eio at ICFP 2023.
Saturn -- Parallel Data Structures
An essential component in the parallel programming toolkit is a library of parallel data structures. A sequential stack or queue data structure is fairly uncontroversial, and it is common to have only a single stack or queue implementation in the language. Indeed, we have a single stack and a single queue data structure in the OCaml standard library. The addition of parallelism brings an explosion of possibilities and challenges:
- Correctness -- the addition of concurrency makes it much harder to reason about the correctness of the data structures.
- Specialisation -- the performance of the data structure varies widely based on the number of parallel threads accessing the data structure. Hence, it is common to have specialised data structures that are optimised for a limited number of threads and capacity, such as single or multiple producers and consumers to bounded or unbounded queues.
- Progress -- Should a pop operation on an empty queue block the caller or should it return immediately with a
None? Both options are useful in different circumstances, but supporting one or the other will mean very different tradeoffs and hence, different implementations. Moreover, the non-blocking options are further classified in literature based on the progress in the presence of concurrent operations. - Composability -- In a typical parallel data structure each of the individual operations such as a push or a pop is atomic. What if our application demands that multiple operations be performed atomically? Putting a lock around the entire thing does not often work since it affects performance non-trivially and introduces correctness issues such as deadlocks. There are other mechanisms for well-behaved composition such as software transactional memory.
In other languages, this explosion in the state space often leads to a multitude of concurrency libraries, with overlapping features and different trade-offs, often not clearly labelled. Developers frequently face a challenge choosing the right library with the right trade-off. The correctness of the implementations is also often unclear.
At Tarides, we have been working towards Saturn, a library that brings together all of our efforts at building parallelism-safe libraries. Saturn will consist of lock-free and lock-based, blocking and non-blocking, composable and non-composable parallel data structures under one roof. Each of the different data structures will have a default version that is good enough to be used for parallelism and will have well-documented variants with clearly labelled tradeoffs.
Our composable atomic data structures are built over the kcas library which provides a software transactional memory (STM) on top of lock-free multi-word compare-and-swap (MCAS) primitive. While the kcas library implements MCAS in software efficiently, with the arrival of Power backend in OCaml 5, we plan to explore the promise to utilise hardware transactions for MCAS.
To ensure correctness, Saturn data structures are model-checked using dscheck, an experimental model checker for OCaml that cleverly exploits effect handlers to mock and control parallel scheduling. We also plan to continuously benchmark the data structure to monitor any performance regressions. We expect Saturn to be released in Q3 2023.
Domain-Local Await
With OCaml 5, there are several notions of concurrency:
- Domains -- OS threads potentially running in parallel on different cores
- Systhreads -- OS threads on a given domain that timeshare a domain
- Fibers -- Lightweight, language-level threads implemented by the concurrency library. Each concurrency library may have its own scheduler.
This makes the task of writing blocking data structures, such as blocking channels, challenging because the blocking mechanism is specific to each notion of concurrency. Ideally, we would like to write blocking data structures that are parametric over the blocking mechanism so that we can describe blocking channels once and for all of the different notions of concurrency.
To this end, Tarides has been developing domain-local await (DLA), a scheduler-independent mechanism for blocking. The goal is that concurrency libraries provide the implementation of the DLA interface, and with this, they can use blocking data structures from Saturn. For example, with the implementation of a DLA interface in Eio, it is able to utilise blocking transactions in kcas. By separating out the blocking mechanism from the blocking data structures, different concurrency libraries such as eio and domainslib may communicate easily. At Tarides, we are exploring other scheduler-independent mechanisms for timeout and io.
Multicore Testing Tools
The task of moving a large OCaml codebase to take advantage of new OCaml 5 features may seem daunting. It is likely that none of the existing code was written with concurrency and parallelism in mind. Tarides has been working to empower software engineers with multicore testing tools in order to ease the process of using the new OCaml 5 features.
Thread Sanitizer
When parallelism is introduced in a code base, there is the risk of introducing data races. A data race is said to occur when there are two accesses to a memory location, with at least one of them being a write, and there is no synchronisation between the accesses. For example, the following program:
let r = ref 0
let d = Domain.spawn (fun _ -> r := 1)
let v = !rhas a data race, since the main domain and the newly spawned domain d race to access the reference r, and there is no synchronisation between the accesses.
As a pragmatic language, OCaml encourages the use of mutable state with primitive operations such as reference cells, mutable record fields, arrays, and standard library data structures such as hash tables, stacks, and queues with in-place modification. Thus, it is likely that the addition of parallelism to an OCaml code base will introduce data races.
In C++, the behaviour of a program with data races is undefined. In OCaml, the situation is much better. OCaml programs with data races have well-defined semantics. In particular, a program with data races will not violate type safety and will not crash. That said, the programs with data races may produce behaviours that cannot be explained only by the interleaving of operations from different threads. Hence, it is important that data races are detected and removed from the code base.
To this end, Tarides has developed Thread Sanitizer (TSan) support for OCaml. TSan is an approach developed by Google to locate data races originally for C++ code bases. It works by instrumenting executables to keep a history of previous memory accesses (at a certain performance cost) in order to detect data races, even when they have no visible effect on the execution. TSan instrumentation has been implemented in various compilers (GCC, Clang, as well as the Go and Swift compilers) and has proved very effective in detecting hundreds of concurrency bugs in large projects. Executables instrumented with TSan report data races without false positives. However, data races in code paths that are not visited will not be detected.
Tarides engineers have used TSan successfully to port large non-trivial code bases such as the work-in-prograss port of Irmin to Multicore. The response from the developers using TSan has been overwhelmingly positive. A particularly attractive feature of TSan in OCaml is the ease of use. The developer merely needs to install a different compiler switch with TSan enabled, and without any additional work, TSan reports data races with accurate backtraces for the conflicting accesses. A PR for adding TSan support for OCaml is currently open. TSan support for OCaml is likely to appear in OCaml 5.2.
Property-Based Testing
Data races are just one of the hazards of parallel programming. Even without data races, the program may produce different results across several runs due to non-determinism. How can the developers gain more confidence about the correctness of their implementations? To this end, we have been developing two property-based testing libraries namely Lin and STM.
In property-based testing, the programmer provides a specification about the program that should remain true and the system tests that the properties hold under a large number of different executions, typically randomly generated inputs. In the case of Lin and STM, the program is tested under different interleavings of domains. Lin tests whether the results obtained under parallel execution correspond to the same operations applied one after the other in a sequential execution. STM take a pure model description and compares the results to the actual results seen in a parallel execution.
Both libraries have been extremely effective in identifying issues in the standard library under parallel execution. The OCaml standard library was implemented without parallel execution in mind. While much of the standard library is not parallelism-safe, we do not expect parallel access to the standard library to crash. Lin and STM have been particularly successful in identifying crashes. We believe that Lin and STM will help OCaml 5 developers gain more confidence that their code is correct under parallel execution.
Call for Action
If you have an existing OCaml code base, please try OCaml 5 today. If you find regressions, please file an issue on the OCaml GitHub repo. If you are considering utilising the new OCaml 5 features, please give the concurrency libraries and the tools a go. We would love to hear whether the libraries and tools work for you. File issues in corresponding repos if you find anything that is amiss. If you are looking for commercial support on any of these topics, do not hesitate to contact us.
All of the work discussed in this post are open-source. If you wish to contribute to these efforts, please look for the "good first issue" tag in any of these repos. If you are looking to learn, please head over to the community section to ask us questions and share and discuss OCaml-related topics.
Happy hacking!
HideWe're sponsoring SoME3 — Jane Street, Jul 06, 2023
Jane Street is excited to announce our sponsorship of SoME3, Grant Sanderson and James Schloss’s third Summer of Math Exposition. SoME is a contest that Grant and James created to encourage the development of fun and interesting mathematics education videos.
Florian's OCaml compiler weekly, 5 July 2023 — GaGallium (Florian Angeletti), Jul 05, 2023
This series of blog posts aims to give a short weekly glimpse into my (Florian Angeletti) daily work on the OCaml compiler. The subject this week is a cartography of the source of opam packages breakage in OCaml 5.1.0 .
With the recent release of the first beta for OCaml 5.1, I have spent some time at the state of the opam ecosystem looking for package that broke with OCaml 5.1 .
Interestingly, for this beta there most of those incompatibility stemmed from 7 changes in OCaml 5.1, which …
Read more...This series of blog posts aims to give a short weekly glimpse into my (Florian Angeletti) daily work on the OCaml compiler. The subject this week is a cartography of the source of opam packages breakage in OCaml 5.1.0 .
With the recent release of the first beta for OCaml 5.1, I have spent some time at the state of the opam ecosystem looking for package that broke with OCaml 5.1 .
Interestingly, for this beta there most of those incompatibility stemmed from 7 changes in OCaml 5.1, which is a small enough number that I can list all those potentially package-breaking changes in this blog post.
Stdlib changes
Unsurprisingly, most of the package build failures finds their source in small changes of the standard library. Those changes accounts for at least 8 package build failures in the opam repository at the time of the first beta release.
Updated module types in the standard library
More precisely, one source of build failure is the changes in module types defined in the standard library. Such module types are a known source of backward compatibility difficulty. Depending on the uses of those module types, any change in the module types can create a build failure.
And OCaml 5.1 updated three of such module types.
First, the hash function inside the
Hashtbl.SeededHashedType module type has been renamed to
seeded_hash. This changes make it possible for a module to
implement both Hashtbl.SeededHashedType and
Hashtbl.HashedType (#11157).
Unfortunately, this change breaks modules that were using
Hashtbl.MakeSeeded with the previous signature for the
argument of the functor.
When the change was proposed there were only 6 opam packages affected
by this change. Thus, the improved usability for the
Hashtbl.MakeSeeded functor seemed worth the price. And at
the time of the first beta release, I have only seen two remaining
packages still affected by this change.
Second, a more subtle problem occurred for libraries that were using
the Map.S or Set.S module types: the
signatures has been expanded with new functions (to_list
for Set.S and to_list of_list,
and add_to_list for Map.S).
Consequently, three libraries that were defining new Map
or Set functors using this signature as a constraint need
to add those missing functions to their Map and
Set implementations. Those failures are maybe less
surprising: if one library use a module type provided by the standard
library for one of its own implementation, it inevitably couple strongly
itself to the standard library specification.
New modules in the standard library
Another source of difficulty is that the standard library has been
added a new Type module in OCaml 5.1. This new module
defines the well-know equality GADT (Generalized Abstract Data
Type):
type (_, _) eq = Equal : ('a, 'a) eq
and type identity witnesses. In other words, this is mostly a module for heavy users of GADTs.
Normally, adding a new module to the standard library can be done
painlessly: Standard library modules have a lower priority compared to
local modules. Thus, if someone has a project which defines a
Type module, the non-qualified name Type will
refer to the local module, and the standard library module will be
accessible with Stdlib.Type. However, this low priority
behaviour requires some special support in the compiler and alternative
standard library lacks this support. Consequently, libraries (at least
three) that are defining a local Type module while using
alternative standard library (like base) might be required
to find a non-conflicting short-name for their local Type
module (which might be as simple as
module Ty = Type
open! Base
)
Internal API changes
The second ex æquo source of build failures in opam packages is the changes in internal API, either in the OCaml runtime or in the compiler library.
Changes in the runtime internal API
The internal runtime function caml_shared_try_alloc now
takes the number of reserved bits in the header as a supplementary
argument. This change affected at least one opam package.
Change in the compiler-libs API
To improve the rendering of weakly polymorphic row variables, OCaml 5.1 has switched its high-level display representation of type aliases to make it easier to display “weakly polymorphic aliases”:
[> `X of int] as _weak1
rather than
_[> `X of int]
This caused a build failure for at least one package that was relying on the previous API.
Type system change
The third ex æquo source of build failures is small changes in the type system, where package that were at the frontier of the technically correct and bugs ended up falling on the other side of the fence during this release.
Inexact explicit type annotation for anonymous row variable
For instance, due to a bug fix, OCaml 5.1 is stricter when mixing explicitly polymorphic type annotations and anonymous row variables. Even with all the precautions described in http://gallium.inria.fr/blog/florian-compiler-weekly-2023-04-28, there was at least one opam package that was affected. On the bright side, this was probably a bug in the lone affected package.
Generative functors must be used generatively
When a functor is defined as an applicative functor
module App() = struct
type t
end
OCaml 5.1 forbids now to apply as if it was a generative functor:
module Ok = App(struct end)
module New_error = App()
Previous version of OCaml did not make any difference between
struct end or () in functor applications and
thus allowed the form App(struct end).
The reverse situation, where a generative functor is applied to
struct end is allowed but emits a warning
module Gen() = struct
type t
end
module New_warning = Gen(struct end)
Warning 73 [generative-application-expects-unit]: A generative functor
should be applied to '()'; using '(struct end)' is deprecated.
This restriction is there to make clearer the distinction between applicative and generative application. But at least $one opam package needed to be updated (at the time of the beta release).
Unique case
Sometimes, there are also backward compatible issue with packages
that were using the compiler in surprising ways. For instance, this
time, one package build failed because it was trying to link without
-for-pack modules compiled with -for-pack,
which happened to sometimes work in previous version of OCaml. OCaml 5.1
took the decision to stop relying on such happenstance, and mixing
different -for-pack mode now always result in an error.
Zero-Day Attacks: What Are They, and Can a Language Like OCaml Protect You? — Tarides, Jul 05, 2023
Zero-day attacks have been getting increased media attention lately, but what are they? And how can we protect ourselves? Google’s Project Zero tracks zero-day vulnerabilities at major software vendors. In 2021, their tracker noted the detection and disclosure of 58 in-the-wild zero-day exploits, which was more than any other year since they started tracking in 2014. This suggests an increased awareness of zero-days among the community of developers, explaining the increased number of reports.
Read more...Zero-day attacks have been getting increased media attention lately, but what are they? And how can we protect ourselves? Google’s Project Zero tracks zero-day vulnerabilities at major software vendors. In 2021, their tracker noted the detection and disclosure of 58 in-the-wild zero-day exploits, which was more than any other year since they started tracking in 2014. This suggests an increased awareness of zero-days among the community of developers, explaining the increased number of reports.
This article will give you an overview of what zero-day attacks are, as well as some of the ways to limit the risks they pose. One way to mitigate zero-day attacks is to utilise a secure-by-design language such as OCaml. In this post, we shall see how OCaml promotes secure-by-design software construction practices and how this mitigates the threat of zero-day attacks. There is a lot that could be said on this topic, and this post will only scratch the surface, but it will be a good introduction and overview to an aspect of OCaml that's not talked about enough!
Zero-Day Attacks and Trends
Some basics first: Zero-day attacks are so called because they describe a scenario where threat actors take advantage of an as-of-yet unknown vulnerability in the code of the target. The purpose of the hacks varies; it could be used to introduce various forms of malware into the target’s computer, including ransomware, or to gain access to private identifying information for a phishing scam.
Since it’s an unknown and unpatched vulnerability, the developers are said to have ‘zero days’ to respond to the threat. This also means that whatever antivirus program someone may have in place will be unequipped to handle the threat. This makes the target incredibly vulnerable, being unprotected for the time it takes to release a security patch for the issue – not to mention the time it will take for all users to install that patch.
Hackers and researches are incentivised to find vulnerabilities by the significant pay-outs offered by private companies that buy and sell zero-day exploits. These companies act as brokers and resell the zero-day exploits to interested parties. Exploits that are in high demand can sell for sums in excess of one million US dollars. Since the market isn't regulated, it’s hard to track what a buyer uses an exploit for once it's been sold.
Contrary to popular belief, every major operating system can be hacked and exploited as a result of a zero-day attack. While significantly more zero-day attacks are targeted towards Microsoft Windows rather than Apple’s macOS, this is a result of their proportionately larger market share. Essentially, the more users it has, the more attractive the platform is to attackers,. Attacks on macOS and iOS still happen.
Furthermore, the strengthening of cybersecurity measures across the board has made zero-day attacks a more attractive option for cybercriminals. Rather than trying to circumvent increasingly strong protective measures, hackers are opting for finding unguarded software vulnerabilities and new attack vectors.
The danger posed by these attacks can affect end users in unpredictable ways. For example, if a financial institution is targeted through software they use, hackers could steal sensitive financial information and conduct fraudulent transactions. This could in turn put the company’s customers at risk. In this way, zero-day attacks are a worry for everyone, as in our increasingly digital world we all have something to lose to a cyberattack.
Secure-by-Design, a Possible Solution?
With the rise of zero-day attacks and exploits, focus has shifted to the way software systems are designed. In a report created by the Cybersecurity and Infrastructure Security Agency (CISA) they, together with several partners including the Federal Bureau of Investigation (FBI), Australian Cyber Security Centre (ACSC), Canadian Centre for Cyber Security (CCCS), and the United Kingdom’s National Cyber Security Centre (NCSC-UK) emphasise the need for a fundamental change in how cybersecurity is incorporated in the products and services that technology manufacturers deliver. The report states that:
Historically, technology manufacturers have relied on fixing vulnerabilities found after the customers have deployed the products, requiring the customers to apply those patches at their own expense. Only by incorporating secure-by-design practices will we break the vicious cycle of creating and applying fixes.
Instead of reacting to vulnerabilities as they become known, developers should focus on making their software intrinsically more resistant to attack by incorporating secure-by-design principles from the start. This may come with a trade-off with increased development times now, but with the understanding that it will be gained back later in time saved by not having to release patches and respond to threats. The report reenforces the severity of the threat that cybersecurity vulnerabilities pose and the pressing need for lasting solutions.
Zero-Day Attacks and OCaml
How does OCaml factor into the fight against zero-day attacks and cybersecurity exploits? OCaml is an example of a language that supports secure-by-design practices. Some of its core features already protect you against the most common attacks, and there are several projects using OCaml’s strengths to address cybersecurity threats both known and unknown.
Memory Safety and Zero-Day Attacks
Memory safety issues are maybe the most well-known vulnerabilities that zero-day attackers target. In languages where memory is manually managed, like C, C++, or Assembly, cybercriminals can try to ‘trick’ the program to write to memory incorrectly. These types of attacks typically come in the form of buffer overflows, race conditions, page faults, null pointers, stack exhaustion, etc. Memory related attacks make up the vast majority of zero-day attacks, about 70%, which makes them a serious consideration for any business or organisation.
Memory-safe languages, on the other hand, protect the user against these kinds of attacks simply because they're not possible. Examples of memory-safe languages include OCaml, Java, Rust, and Swift. In OCaml, the compiler provides strong guarantees to ensure that a pointer is only allowed to read and write into the portions of memory intended by the developer (spatial safety). In other languages, like C or C++, this is not the case, so pointers may be exploited to access data outside of the intended structure's memory. The OCaml compiler statically guarantees, at compile time, that a pointer to a record cannot be used to access memory outside of that record – making the language memory-safe.
OCaml also provides temporal safety. In C, the heap memory is manually managed by the developer who decides to allocate free memory. This can lead to use-after-free bugs, which may in turn lead to security exploits. OCaml is a garbage-collected language that automatically manages the lifetimes of the heap objects. This makes it impossible to have use-after-free bugs in OCaml, thus preventing a large class of exploits by design.
To read more about memory-safe vs unsafe languages you can check out this article on Gitlab.
Security Through Teamwork in Open Source
Something that’s mentioned less frequently as a tool for reducing the risks of cyberattacks is open-source development of a language or project. The British National Cyber Security Centre has several recommendations for secure development principles, including tips for managing code repositories. It emphasises the importance of thorough reviews for all code before merge. When open-source projects are well managed, the number of code reviews and scrutiny from different individuals contributes to their safety.
Intel emphasises that “vigilant attention to code inspection, patching, and maintenance can help to reduce an organization’s vulnerability to zero-day attacks.” Again, in a large open-source community with appropriate methods for merge approvals and access, the sheer number of peer reviewers and testing helps secure a language or project further against zero-day attacks. More eyes and minds working to find and patch vulnerabilities helps in the effort to stay one step ahead of attackers. OCaml has a large open source community collaborating in this way, as do many projects written in OCaml. Other languages operate similarly, such as Rust and Haskell.
Smaller Attack Surfaces: The Security Features of MirageOS and Unikernels
MirageOS builds on the security features of OCaml to create lightweight and secure applications. Research on MirageOS began in 2008 in response to the rise of virtual machines (VMs) being used to make cloud computing more efficient. Whilst virtualisation brought many benefits, reliance on VMs added “yet another layer to an already highly layered software stack.” This not only made using and hacking on the software more cumbersome, but it also more vulnerable to attacks due to its large size.
MirageOS addresses this by restructuring VMs into modular components called unikernels. These are small, flexible, and secure specialised OS kernels that act as individual software components. Each unikernel is standalone and responsible for one function or task. An application is made up of several unikernels working together as a distributed system. Cybersecurity experts generally agree that the bigger the ‘attack surface’ is, the more vulnerable the application is to attack. Because of their small size, unikernels have a significantly smaller attack surface than equivalent virtualised solutions, which makes them more secure.
The unikernels of MirageOS also benefit from the security features of OCaml, as Anil Madhavapeddy and David J. Scott describe in their paper:
...managed memory eliminates many resource leaks, type inference results in more succinct source code, static type checking verifies that code matches some abstraction criteria at compilation time rather than execution time, and module systems allow the manipulation of this code at the scales demanded by a full OS and application stack.
Combined, the use of OCaml and the unikernel design makes MirageOS an attractive solution with a variety of applications. For example, IoT (Internet of Things) devices face many security challenges, and MirageOS can provide a secure, efficient way to communicate between multiple devices and keep user data safe.
Putting MirageOS to the Test
Don’t just take our word for it, however, but consider the collective efforts of thousands of hackers. In 2015, the MirageOS team decided to put unikernels to the test. They created a ‘piñata’-style security bounty in the form of a unikernel that held a private key to a Bitcoin wallet with 10 BTC. Anyone who could successfully break into the piñata and get the key would walk away with the 10 BTC, no questions asked. Any method of attack was permitted:
The code for MirageOS is all open source, so the code for how unikernels are built is freely accessible. This means that failure on the attacker’s part was not due to imperfect knowledge or secrecy, but a direct result of the strength of the unikernel solution. This gives us a much more realistic impression of how well a unikernel can resist attack.
To encrypt the unikernel’s connection to the internet, the team used OCaml-TLS, a transport-layer security protocol used for securing web services that use the internet and web browsers. Written entirely in OCaml, it benefits from the type- and memory-safety that comes with the functional programming language. This is in contrast to a TLS written in C, which is vulnerable to attack on these fronts.
At the time of launch, 10 BTC were worth around 2000 EUR, and by the time the project ended in 2018, 10 BTC were worth around 200 000 EUR. During the time the ‘piñata’ was live, over 150 000 attempts were made to connect to its bounty. The ‘piñata’ was retired in 2018 with no successful attempts at cracking it open. At the time, the test illustrated the viability of type- and memory-safe unikernels as a secure solution that could withstand continued targeted attack.
This still holds true today, with cybersecurity at the core of MirageOS and unikernels. The experiment itself illustrates an innovative and collaborative way of testing a product that leverages the strength of the open-source development community. The team devised a way of incentivising hundreds of people to scrutinise their public code and try to break into the unikernel. This gave them a sense of their solution's strength and ideas on how they could fortify it further. They have since built on the insights gained from the BTC unikernel ‘piñata’ experiment to strengthen its resistance to zero-day attacks.
Conclusion
By carefully choosing your programming language and software, you can protect yourself, your projects, and your users against zero-day attacks and security threats. Picking a language with strong safety features is crucial to the long-term success and safety of your projects. Due to the high proportion of memory-safety exploits among zero-day attacks, using a memory-safe language gives you an advantage. Attackers are constantly honing their skills and looking for new vulnerabilities to exploit, so choosing software that is resistant to their attempts is an important part of ensuring your projects are secure.
There’s much more to say about OCaml and the potential it has to protect you against cyberattacks, including technical aspects like formal verification which we haven’t touched on here. If you’re looking for the technical details, don’t worry! Just look out for future posts!
If you’re looking for an efficient, high-security solution to protect your sensitive data and think OCaml or MirageOS might be right for you, don’t hesitate to contact us for more information or to get you started. You can also find us on Twitter and LinkedIn.
Sources
Zero-Day Attacks
- ITPro: What's Behind the Explosion in Zero-Day Exploits?
- Intel: What is a Zero-Day Exploit?
- Cynet: Zero-Day Exploits: Examples, Prevention, and Detection
- National Cyber Security Center: Protect Your Code Repository
- TechMonitor: The Zero Day Vulnerability Trade Remains Lucrative but Risky
- Project Zero: The More You Know, The More You Know You Don’t Know
- SIRP: https://www.sirp.io/blog/behind-the-rise-of-the-million-dollar-zero-day-market/
Memory Safety
- GitLab: How to Secure Memory-Safe vs Manually Managed Languages
- ITPro: What's Behind the Explosion in Zero-Day Exploits?
MirageOS
- ACM Queue: Unikernels: Rise of the Virtual Library Operating System
- MirageOS Bitcoin Piñata Results
- Full Stack Engineer: The Bitcoin Piñata - No Candy for You
- Robur: Robur Reproducible Builds
OCaml-tls
Hideopam 2.2.0 alpha is ready! — OCaml Platform (David Allsopp - Tarides, Léo Andrès - OCamlPro, Raja Boujbel - OCamlPro, Basile Clément - OCamlPro, Kate Deplaix - Tarides, Louis Gesbert - OCamlPro, Dario Pinto - OCamlPro, Christine Rose - Tarides, Riku Silvola - Tarides), Jul 03, 2023
Feedback on this post is welcomed on Discuss!
We are happy to announce the alpha release of opam 2.2.0. It contains numerous fixes, enhancements, and updates; including much-improved Windows support, addressing one of the most important pain points identified by the OCaml community. You can view the full list of changes in the release note.
This alpha release is a significant milestone, brought together by Raja Boujbel after years of work from the opam dev team (Raja Boujbel, David Allsopp, Ka…
Read more...Feedback on this post is welcomed on Discuss!
We are happy to announce the alpha release of opam 2.2.0. It contains numerous fixes, enhancements, and updates; including much-improved Windows support, addressing one of the most important pain points identified by the OCaml community. You can view the full list of changes in the release note.
This alpha release is a significant milestone, brought together by Raja Boujbel after years of work from the opam dev team (Raja Boujbel, David Allsopp, Kate Deplaix, Louis Gesbert, in a united OCamlPro/Tarides collaboration) with the help of many community contributors. We also thank Jane Street for their continued sponsorship.
This version is an alpha, so we invite users to test it to spot previously unnoticed bugs and work towards a stable release.
Windows Support
Opam 2.2 comes with native Windows compatibility. You can now use opam from your preferred Windows terminal! We rely on the Cygwin UNIX-like environment for Windows as a compatibility layer, but it is possible for a package to generate native executables.
The main opam repository is not Windows compatible at the moment, but existing
work on a compatible
repository (originally
from @fdopen) and 32/64 bit mingw-w64
packages (by
@dra27) is in the process of being merged. Before
the final release, we expect it to be possible to run opam init and use the
main opam-repository for Windows.
How to Test opam on Windows
This alpha requires a preexisting Cygwin installation. Support for full management of a local Cygwin environment inside of opam (so that it's as transparent as possible) is queued already and should be available in 2.2.0~alpha2 as the default option.
- Check that you have all dependencies installed:
autoconf,make,patch,curl- MinGW compilers:
mingw64-x86_64-gcc-g++,mingw64-i686-gcc-g++ - Or if you want to use the MSVC port of OCaml, you'll need to install Visual Studio or Visual Studio Build Tools
- Download & extract the opam archive
- In the directory launch
make cold - A coffee later, you now have an opam executable!
- Start your preferred Windows terminal (cmd or PowerShell), and initialise opam with the Windows sunset repository:
opam init git+https://github.com/ocaml-opam/opam-repository-mingw
From here, you can try to install sunset repository packages. If any bug is found, please submit an issue. It will help opam repository maintainers to add Windows repository packages into the main repository.
Hint: if you use the MinGW compiler, don't forget to add to your
PATHthe path tolibcdlls (usuallyC:\cygwin64\usr\x86_64-w64-mingw32\sys-root\mingw\bin). Or compile opam withmake cold CONFIGURE_ARGS=--with-private-runtime, and if you change opam location, don't forget to copyOpam.Runtime.amd64(orOpam.Runtime.i386) with it.
Recursive Pin
When installing or pinning a package using opam install or opam pin, opam
normally only looks for opam files at the root of the installed package. With
recursive pinning, you can now instruct opam to also look for .opam files in
subdirectories, while maintaining the correct relationship between the .opam
files and the package root for versioning and build purposes.
Recursive pinning is used with the following options to opam pin and opam install:
- With
--recursive, opam will look for.opamfiles recursively in all subdirectories. - With
--subpath <path>, opam will only look for.opamfiles in the subdirectory<path>.
The two options can be combined: for instance, if your opam packages are stored
as a deep hierarchy in the mylib subdirectory of your project, give opam pin
. --recursive --subpath mylib a try!
You can use these options with opam pin, opam install, and opam remove.
$ tree .
.
├── ba
│ └── z
│ └── z.opam
├── bar
│ └── bar.opam
└── foo.opam
$ opam pin . --subpath ba/z --no-action
Package z does not exist, create as a NEW package? [y/n] y
z is now subpath-pinned to directory /ba/z in git+file:///tmp/recpin#master (version 0.1)
$ opam pin --recursive . --no-action
This will pin the following packages: foo, z, bar. Continue? [y/n] y
foo is now pinned to git+file:///tmp/recpin#master (version 0.1)
Package z does not exist, create as a NEW package? [y/n] y
z is now subpath-pinned to directory /ba/z in git+file:///tmp/recpin#master (version 0.1)
Package bar does not exist, create as a NEW package? [y/n] y
bar is now subpath-pinned to directory /bar in file:///tmp/recpin (version 0.1)
$ opam pin
bar.0.1 (uninstalled) rsync directory /bar in file:///tmp/recpin
foo.0.1 (uninstalled) git git+file:///tmp/recpin#master
z.0.1 (uninstalled) git directory /ba/z in git+file:///tmp/recpin#master
$ opam pin . --recursive --subpath ba/ --no-action
Package z does not exist, create as a NEW package? [y/n] y
z is now subpath-pinned to directory /ba/z in git+file:///tmp/recpin#master (version 0.1)Tree View
opam tree shows packages and their dependencies with a tree view. It is very
helpful to determine which packages bring which dependencies in your installed
switch.
$ opam tree cppo
cppo.1.6.9
├── base-unix.base
├── dune.3.8.2 (>= 1.10)
│ ├── base-threads.base
│ ├── base-unix.base [*]
│ └── ocaml.4.14.1 (>= 4.08)
│ ├── ocaml-base-compiler.4.14.1 (>= 4.14.1~ & < 4.14.2~)
│ └── ocaml-config.2 (>= 2)
│ └── ocaml-base-compiler.4.14.1 (>= 4.12.0~) [*]
└── ocaml.4.14.1 (>= 4.02.3) [*]It can also display a reverse-dependency tree (through opam why, which is an
alias to opam tree --rev-deps). This is useful to examine how dependency
versions get constrained.
$ opam why cmdliner
cmdliner.1.2.0
├── (>= 1.1.0) b0.0.0.5
│ └── (= 0.0.5) odig.0.0.9
├── (>= 1.1.0) ocp-browser.1.3.4
├── (>= 1.0.0) ocp-indent.1.8.1
│ └── (>= 1.4.2) ocp-index.1.3.4
│ └── (= version) ocp-browser.1.3.4 [*]
├── (>= 1.1.0) ocp-index.1.3.4 [*]
├── (>= 1.1.0) odig.0.0.9 [*]
├── (>= 1.0.0) odoc.2.2.0
│ └── (>= 2.0.0) odig.0.0.9 [*]
├── (>= 1.1.0) opam-client.2.2.0~alpha
│ ├── (= version) opam.2.2.0~alpha
│ └── (= version) opam-devel.2.2.0~alpha
├── (>= 1.1.0) opam-devel.2.2.0~alpha [*]
├── (>= 0.9.8) opam-installer.2.2.0~alpha
└── user-setup.0.7Special thanks to @cannorin for contributing this feature.
Recommended Development Tools
There is now a way for a project maintainer to share their project development
tools: the with-dev-setup dependency flag. It is used in the same way as
with-doc and with-test: by adding a {with-dev-setup} filter after a
dependency. It will be ignored when installing normally, but it's pulled in when the
package is explicitely installed with the --with-dev-setup flag specified on
the command line. The variable is also resolved in the post-messages: field
to allow maintainers to share more informations about that setup.
This is typically useful for tools that are required for bootstrapping or regenerating artifacts.
For example
opam-version: "2.0"
depends: [
"ocaml"
"dune"
"ocp-indent" {with-dev-setup}
]
build: [make]
install: [make "install"]
post-messages:
[ "Thanks for installing the package"
"and its tool dependencies too, it will help for your futur PRs" {with-dev-setup} ]Software Heritage Binding
Software Heritage is a project that aims to archive all software source code in existence. This is done by collecting source code with a loader that uploads software source code to the Software Heritage distributed infrastructure. From there, any project/version is available via the search webpage and via a unique identifier called the SWHID. Some OCaml source code is already archived, and the main opam and Coq repository packages are continuously uploaded.
Opam now integrates a fallback to Software Heritage archive retrieval, based on SWHID. If an SWHID URL is present in an opam file, the fallback can be activated.
To keep backwards compatibility of opam files, we added a specific Software
Heritage URL syntax to the url.mirrors: field, which is used to specify
mirrors of the main URL. Opam 2.2.+ understands this specific syntax as a
Software Heritage fallback URL: https://swhid.opam.ocaml.org/<SWHID>.
url {
src: "https://faili.ng/url.tar.gz"
checksum: "sha512=e2146c1d7f53679fd22df66c9061b5ae4f8505b749513eedc67f3c304f297d92e54f5028f40fb5412d32c7d7db92592eacb183128d2b6b81d10ea716b7496eba"
mirrors: [
"https//failli.ng/mirror.tar.gz"
"https://swhid.opam.ocaml.org/swh:1:dir:9f2be900491e1dabfc027848204ae01aa88fc71d"
]
}To add a Software Heritage fallback URL to your package, use the
swhid library. Specifically the
Compute.directory_identifier_deep
function:
- Download opam package archive
- Extract the archive
- Compute SWHID with
Compute.directory_identifier_deep. You can use this oneliner in the directory:ocaml -e '#use "topfind";; #require "digestif.ocaml";; #require "swhid";; Swhid_core.Object.pp Format.std_formatter (Result.get_ok (Swhid.Compute.directory_identifier_deep "."))'
Special thanks to @zapashcanon for collaborating on this feature.
Formula (Experimental)
It is now possible to leverage the full expressivity of package dependency formulas from the command line during switch creation and package operations.
It is possible to create a switch using a formula. For example, with
ocaml-variant or ocaml-system, excluding ocaml-base-compiler:
opam switch create ocaml --formula '"ocaml-variants" {>= "4.14.1"} | "ocaml-system"'This syntax is brought to install commands. For example, while installing a
package, let's say genet, you can specify that you want to install either
conf-mariadb & mariadb or conf-postgresql:
opam install genet --formula '["mysql" ("conf-mariadb" & "mariadb" | "conf-postgresql")]'New Options
Here are several of new options (possibly scripts breaking changes are marked with ✘):
opam pin --currentto fix a package to its current state (disabling pending reinstallations or removals from the repository). The installed package will be pinned with the opam file that is stored in opam internal state, the one that is currently installed.opam pin remove --allto remove all the pinned packages from a switch.opam pin remove pkg.versionnow removes the pins on pinnedpkg.version.opam exec --no-switchto remove opam environment from launched command.
$ export FOOVAR=env
$ opam show foo --field setenv
FOOVAR = "package"
$ opam exec -- env | grep "OPAM_SWITCH\|FOO"
FOOVAR=package
OPAM_SWITCH_PREFIX=~/.opam/env
$ opam exec --no-switch -- env | grep "OPAM_SWITCH\|FOO"
FOOVAR=envopam source --no-switchto allow downloading package sources without having an installed switch (instead of failing).opam clean --untrackedto remove untracked files interactively remaining from previous packages removal.opam switch -, inspired fromgit switch -, that goes back to the previously selected global switch.opam admin add-constraint <cst> --packages pkg1,pkg2,pkg3to select a subset of packages to apply constraints.✘ Change
--baseinto--invariant.opam switchcompiler column now contains installed packages that verifies invariant formula, and empty synopsis shows switch invariant.
$ opam switch create inv --formula '["ocaml" {>= "4.14.1"} "dune"]'
$ opam switch invariant
["ocaml" {>= "4.14.1"} "dune"]
$ opam list --invariant
# Packages matching: invariant
# Name # Installed # Synopsis
dune 3.8.2 Fast, portable, and opinionated build system
ocaml 5.0.0 The OCaml compiler (virtual package)
$ opam switch list
# switch compiler description
→ inv ocaml-base-compiler.5.0.0,ocaml-options-vanilla.1 ocaml >= 4.14.1 & duneTry It!
In case you plan a possible rollback, you may want to first backup your
~/.opam directory.
The upgrade instructions are unchanged:
From binaries: run
bash -c "sh <(curl -fsSL https://raw.githubusercontent.com/ocaml/opam/master/shell/install.sh) --version 2.2.0~alpha"Or download manually from the Github "Releases" page to your PATH.
From source, manually: see the instructions in the README.
Then run:
opam init --reinit -niPlease report any issues to the bug-tracker.
Thanks for trying this new release out, and we're hoping you will enjoy the new features!
HideEmelleTV: Talking with Louis Roché about OCaml and Ahrefs — Ahrefs, Jun 29, 2023
Transcript
David: [00:00:00] Hello, my name is David. I run EmelleTV. It’s a talk show about OCaml, ReScript, and Reason. I often bring guests from the community to talk about them and meet them and asking a lot of questions about the language or what they’re working on, and of course having fun with Hindley–Milner type system. That’s part of the show. I work for Ahrefs, it’s actually this company.
Today I’m interviewing a …
Read more...Transcript
David: [00:00:00] Hello, my name is David. I run EmelleTV. It’s a talk show about OCaml, ReScript, and Reason. I often bring guests from the community to talk about them and meet them and asking a lot of questions about the language or what they’re working on, and of course having fun with Hindley–Milner type system. That’s part of the show. I work for Ahrefs, it’s actually this company.
Today I’m interviewing a coworker, so it’s going to be a little bit a branded stream. Hope you understand. It’s a lovely company. Apply if you’re looking for a job to work on OCaml or Reason. Aside from that, I maintain styled-ppx and implementation of React on server, but that’s just enough about me, and I’m going to introduce our guest, Louis. Hello, Louis. How are you?
Louis: [00:00:59] Good, and you?
David: [00:01:01] Good. Very good. You obviously work at Ahrefs. At what team do you work?
Louis: [00:01:10] This is recently changing, but I have been in the back-end forever, since like seven years ago and I still have some of the projects that I had when I joined. This was stable. I’m in this new team called middle-end. Ahrefs is not very good with naming. We say that it’s the hardest thing in computer science. We have front-end that is actually full stack, then we have a back-end, which is more like data, and now we have middle-end, which is somewhere in the middle. I’m supposed to lead this new middle-end team.
David: [00:01:48] Nice.
Louis: [00:01:49] We’ll see how it goes.
David: [00:01:49] Nice. Today I think we’re going to answer a few questions about Ahrefs, I think has been a mysterious company, if you look at it from the outside. When I joined, I think you helped me understand a lot of things that I didn’t know about Ahrefs. I might just fire the same questions that I did, just recorded so everybody can understand them. Aside from from Ahrefs, who are you and can you present a little about yourself?
Louis: [00:02:21] This is a tough question. Who am I? I grew up in France. I’m French, still I’m French, but I’ve been living in Singapore for seven years, with Ahrefs for seven years. I’ve been working in OCaml my whole life basically because my first job was in OCaml, and Ahrefs which is my second job, is in OCaml too. I cannot say that it’s better than the rest because I never tried the rest. I’ve been involved with OCaml, like the OCaml meetup in Paris for some time.
I’m on the online community. I’m part of the OCaml Code of Conduct committee, which is an effort that was started last year, I think. So far we don’t have a lot of work, so that’s good. I’m one of five doing this. Then outside of that, I’m a pretty normal person. I’m 31 years old, and that’s about it, I would say.
David: [00:03:35] That’s the whole idea. You have been been writing OCaml for a long, long time. That’s fair to say.
Louis: [00:03:40] I’ve been writing OCaml since I’m 16 or 17 was when I wrote my first line, like 14 years ago, something like this. There was no Merlin at the time.
David: [00:03:52] There was no LSP. The first question is, 15 years, this is a long time, but how do you see the evolution of entire language? Would you split it in chunks? How have you seen the progress of the language?
Louis: [00:04:08] It’s hard to say. When I joined the OCaml world, it was because of people who nowadays are fairly important like Gabriel Scherer, who’s working in Inria, I think, but he’s one of the main maintainer for OCaml. He was in this French forum, pushing very hard people to try OCaml and I got convinced. I started just writing a few lines here and there, and then I just stick to that for a long time. I’ve been mostly a user like this. My usage has extended over time, but I’ve never been called a contributor. My point of view is more as a user.
The biggest difference is the size of the community, I would say. It’s much more dynamic than it used to be. We used to install packages like OCaml libraries, using Debian packages. It was apt install something. There was no opam, there was no Merlin, there was no vscode, right?
David: [00:05:25] Right.
Louis: [00:05:25] LSP didn’t exist, so way less library. I think you can see today how it was in the past because you can see, we have 10 different libraries to do HTTP 1.1. We have 10 different standard libraries, and it’s legacy of what OCaml was in the past. We used to have all those smart people, but they had no way to collaborate. There was no opam, there was no way to share your work. Everyone was smart enough to rewrite —
David: [00:06:04] Build your own library for http.
Louis: [00:06:05] Yes.
David: [00:06:06] Right. That’s always interesting for me, how OCaml got so many different things that are hard to create, like standard libraries. I think recently, Containers reached 10 years, so it’s like what? [chuckles] It doesn’t make much sense. If you look at now, it doesn’t make much sense, but if you look at historically, it does make sense.
Louis: [00:06:35] When you have no choice, you do it. You don’t know that it’s harder, you just see “Oh, I can do it,” and you do it.
David: [00:06:42] Yes. You need to think it’s easy. You need to start a standard library or http library saying, “Oh, it’s easy.” Then, you start a little bit, and eventually, you create something. Last week — Oh, sorry, go on.
Louis: [00:06:57] No, go ahead.
David: [00:06:59] Last week, I tweeted that OCaml suffers a lot from the Python Paradox. The Python Paradox, I think somebody write it, I think it was, I don’t remember the name of the guy, but somebody write it in 2004, that when you use Python for a company, and you get the smartest people that they want to innovate, and you have the pioneers of the language. Then, by default, you try to hire people that are in love with software, so eventually, they create good software or they are willing to suffer from getting out of the comfort zone and create software. I believe the combination is the same spot. Can you see, is that true? Do you agree?
Louis: [00:07:49] I don’t know if that’s true. Partially, it’s a strategy of Ahrefs, so I have to say it’s true.
David: [00:07:55] [laughs]
Louis: [00:07:58] Yes, I think it’s partially true, but it’s not completely correct. For OCaml, at least it’s a bit different from Python, because OCaml has this strong academic influence, so a lot of people are actually researcher. There is a big benefit that they have, not free time, but they manage their time, they manage what they work on, and they decide what is important. They got all this time to actually write this complicated code many times because actually, it’s part of their job to just redo the same thing in better ways. It’s normal you have to explore a subject.
It’s okay to do it multiple times. It’s a combination of those people are working in the right place, they have the right time, and they have the correct background. A lot of people were working on subjects that allowed them to do it. Some, it’s because they were very strong in writing languages. Some, it’s because they have this strong Unix background, I would say.
David: [00:09:05] Right. It’s very unixy. The start of OCaml is very unixy. That’s true.
Louis: [00:09:14] Xavier Leroy wrote LinuxThreads, I think that was used in Linux forever, so there is this background. Probably, it’s a bit different in Python because it grew more in the industry rather than in an academic setup. For sure, if you try to target people who live in a niche, you find people with a different interest from the main programming community, I would say. At the same time, I think some of the best meetup or conference I’ve been to were Java meetup.
David: [00:09:59] All right.
Louis: [00:10:00] They know that their language is boring. The language is the same since 20 years or 30 years. There are some changes but they don’t really care about the language too much. It’s a huge, huge community. Basically, everything already exists. There is no big bragging, everyone can do everything. There are 10 versions of everything, whatever. The benefit is that they are super open-minded.
Oh, something is new. Something is different. Okay. Let’s see that. You go to that meetup and they will not talk only about all the fancy new feature in Java. It’s like, “Oh, I saw this new git tool. Oh, it’s funny. Okay, let’s try to use this.” A new way to do web development. Okay, let’s study the subject. It’s not about Java itself because the language is not interesting enough. It’s about other programming stuff. It’s very fun to attend.
David: [00:11:03] That’s a good one. Actually, many people that now are starting to hear OCaml for the first time, after they leave or they got disappointed with the Rust policy drama. These people cannot get into OCaml because some influencer wanted to bash on Rust. They started exploring all the languages and of course Ocaml was one of those. Aside from Zed or whatever you compare it with, low level programming languages. Do you see those influencers move people to actually try the language and deploy it into users and doing serious stuff, or it’s more like vain marketing?
Louis: [00:11:56] I’m not a big Twitch person. I don’t know [crosstalk] modern influencers.
David: [00:12:02] That’s true.
Louis: [00:12:03] I think it exists in two forms. In the past it existed in two forms. You had influencers, you had Rob Pike and- who’s the other person? The two person who are behind Go. They do not make a good language but they are influencers. They were like, “Oh, yes. We did UTF-8 and a Plan 9 in the past and we work at Google. Oh, it’s going to be amazing.” No, it’s a crappy language, but they are influencers. They move people.
David: [00:12:32] [laughs] Okay. Would you say that Go is crap?
Louis: [00:12:38] Go is a language. I haven’t used Go 2 extensively.
David: [00:12:42] This is recorded. This is not a beer in Singapore. This is recorded. You can obviously bash go, that’s part of the game.
Louis: [00:12:50] Let’s say Go is not the most modern language there is.
David: [00:12:54] Right. Thank you. This is just for the headline. We don’t want the headlines- because Ahrefs is going to be like — No, I’m joking. [crosstalk] Yes, go on. Sorry.
Louis: [00:13:10] On the same topic of influencer, we saw it with Reason. When the Reason comes, it’s not just a random person creating Reason. It’s Jordan and he comes with a React background, and he comes with followers. He is not doing videos online but it’s the same idea. I think yes, it has definitely an influence and OCaml grew a lot when Reason started.
David: [00:13:38] Yes, that’s true.
Louis: [00:13:39] I definitely think it has an influence.
David: [00:13:43] That’s true. From the community, how have you seen the Reason creation and adoption from your point of view? You can bash Reason if you want.
[00:13:43] [crosstalk]
Louis: [00:13:56] At that time I think the OCaml community was one IRC channel. It was a bit different from now. I think what I was not super convinced by when Reason to syntax arrived, I think the original claim by Jordan was he’s making a better syntax. I was not super convinced that the syntax was better. It was developed independently from OCaml.
By experience I already knew at the time that if you start to fork or develop on your side and don’t integrate fairly quickly with upstream it’s actually never going to be integrated with upstream.
David: [00:14:53] Right.
Louis: [00:14:54] I don’t know why exactly, but it has happened a few times. Then there is a question of bucklescript because if you write Reason it’s two sides. There is a syntax which I only partially understood too because I was not a web developer, I’m still not a web developer. I did not know about JSX. I did not know how powerful it was and I think React was not as big at the time too, but I think JSX is a nice idea and there are a lot of things in the syntax that are nice, like parentheses around arguments is a problem but it has some benefits, too.
David: [00:15:42] Yes, I think some trade-offs from OCaml, or at least some edge cases from the syntax from OCaml got resolved in Reason just by adding more- like the parentheses or the braces or the semicolons. But yes, the others are, can remove some problems from the syntax. Not problems, but just the edge cases from the cleanness for OCaml.
Louis: [00:16:10] Yes. Even sometimes it’s not edge case but it’s nice to see very clearly for example, when you apply a function, where are the arguments? Where it starts where it ends? There are benefits, obviously, like the OCaml syntax or Haskell syntax is lighter, we will say, have some benefits. The other one is nice, too.
David: [00:16:36] Yes, definitely and you mentioned BuckleScript?
Louis: [00:16:40] Yes. BuckleScript, they didn’t have —
David: [00:16:42] That was not so well received.
Louis: [00:16:47] Yes, I think because there was Js_of_ocaml idea. There was js_of_ocaml and so again, it was like yes, I do something different and- I think Bob developed it fully inside Bloomberg at the time. Basically, he came out and he had, “Oh, yes, I have a new project and it’s working already.” He didn’t start to develop it in public. The community was much smaller, too so every time you split efforts like this, it’s kind of costly. People will say, “Yes, we will try to collaborate. We’ll try to make the two projects work together,” or whatever and it never works. Never works. I don’t think I understood all the trade-off. I’m happy that I invited Bob to the OCaml meetup in Paris which retrospectively, it was a good thing to do.
David: [00:17:50] Yes, for the record, Louis was running the OCaml Paris Meetup, I think. Yes, go on with the story.
Louis: [00:18:00] Yes, so when I moved to Singapore, I still organized one meetup, even though I was in Singapore and I invited Bob to present BuckleScript. At the time, it was a bit controversial, because many people were a bit unhappy with what he was doing, but I’m happy that I did it. I didn’t understood what I was doing exactly but at the end, I think it was the right thing to do. Even if the project died later on, you have to give such projects a chance.
David: [00:18:35] Yes, I think I wouldn’t say that BuckleScript died. It’s more like BuckleScript has been working for seven years, I think.
Louis: [00:18:42] Yes, no, even if it was a failure, which it was not, but maybe like six months later, it could have died and disappeared. Yes, I think when people have a drastically different approach, usually they have a reason. It’s worth listening. A lot of what Bob defended, I’m not sure I completely agree with it. He wants a very stable compiler, for example. He said, in Bloomberg, they are using GCC 3 or 4, I don’t remember, since forever.
So they don’t need to upgrade the compiler, the GCC compiler, for example. He thought the same idea can apply to OCaml, we don’t need to follow the upstream compiler all the time.
David: [00:19:27] Right. Yes.
Louis: [00:19:29] Most companies actually they don’t want to change compiler version. They want something stable. They want no surprise, which has some value, or the stability has some value.
David: [00:19:40] Yes, that’s true but I think when he mentioned about the compatibility with the compiler, I think it’s mostly OCaml has been very stable since, what 6, 7 years ago, I think. I think there were some small changes or some addition features, but nothing really break, but mostly the syntax. Then he complained about the parsing, like the AST modifications, those were present, those were changing between versions. He wanted to not- because BuckleScript is a fork of the common compiler and embedded into ReScript now.
Yes, he was complaining about the AST transformations because every version changes a lot. There are migrations. You could write some logic to migrate from one to another. It’s painful if you maintain a fork of this, you might suffer a lot from updating from one compiler to another.
Louis: [00:20:41] Yes, and I think for him, even as an end user, the stability has some value. It’s interesting for him to have a stable compiler and even for his target, the people he’s targeting, the stability has some value too.
David: [00:21:00] After you mentioned that people were installing or sharing libraries through Debian packages, which maybe- I’m as old as you, but maybe I’m too young to see how those package managers could work with apt get. What’s the position of the tooling? Right now I think we are in a state where we have two bigger players such as opam and dune, as Package Manager and Build Infrastructure, we’d call it, I don’t know. Now dune is exploring installing packages. How do you see the tooling these recent years?
Louis: [00:21:48] It’s amazing. It’s completely incredible. Then people will have different opinions on is opam perfect or whatever. If you compare to what it was before, it’s incredible. I think even if you compare to other languages, it’s a fairly solid experience now. Opam is working well. You just need to learn the UI, but it’s working fairly well. Dune is relatively fast, easy to use. The LSP is pretty magical. Merlin is a very solid tool. It was one of the first, I think I would say, like a small language with a tool as powerful as Merlin.
It’s not only powerful, it’s avantgarde. It understood already that you had to be able to do error recovery and that you had to change the way you parse files to be able to work with something that is half broken.
David: [00:22:57] Yes, that’s true.
Louis: [00:23:00] The people behind Merlin are super smart. In a way, it’s not a surprise.
David: [00:23:05] Right. You actually contributed to the LSP and dune, to both projects, I saw your contributions.
Louis: [00:23:13] Yes, I have commits on many small- it’s mostly small contributions, but I have commit on everything, I think at some point.
David: [00:23:19] Right.
Louis: [00:23:21] LSP, I participated in putting some ppx deriving stuff and I wrote a bunch of commands. I implemented some Merlin behavior inside LSP. If you hover multiple times on the same value, the type will be more and more verbose. I took this behavior back to LSP. Dune I have mostly bug fixes, probably small documentation, nothing big.
David: [00:23:58] One of the things that you mentioned as well, I think we talked about this before. When OCaml was very young, all features that got added into the language were PhD projects, where it’s a student that is very passionate or maybe just his guidance is OCaml fan, he just explored with a language in the theory on academia. Then he worked on a paper and eventually it gets released as part of the language. That was the times where maybe Jane Street not even started using OCaml seriously. Do you see that now? Do you see that those features or academic features got into language? Do you think it’s a weird mix now or they compose well together? How do you see language after these contributions?
Louis: [00:25:04] I was looking today at the OCaml change log because I was wondering when was the release of OCaml 4, and that was 11 years ago because OCaml 4 is- before to OCaml Multicore is the last time there was a big change which was GADT. In the meantime there was mostly small changes. I don’t think the language changed much. If we look what were the big features we could say like the objects in OCaml, GADT, OCaml Multicore.
They all were developed by people in a research setup and somehow it seems to work. I’m not a maintainer on OCaml. I think it works also because they don’t have a lot of energy to integrate a lot of new features, they are very, very picky on what they actually accept in the compiler. Only the most solid implementations will get in.
David: [00:26:36] Yes, that’s true. I think the quality is something that everything core team members says all the time that all these things would be amazing to do but our quality bar is very high. Yes, you need to work on it much more to let us just even look at it. Yes, that’s true.
Louis: [00:26:54] Then there are things that do not compose super, super well. There are part of the module language and part of the object language that do not compose very well. You can make the compiler more or less blow up or the compilation time will become crazy. Actually, those are parts that I don’t know very well. I very seldom combine first-class modules and objects.
David: [00:27:21] Objects, yes. That’s something I haven’t done yet. I think the only experience with that combination might be ppxlib maybe, because you have the traversers. Yes, you use them. You instantiate the traverser. You don’t do anything with internal states of anything. Good point. One thing that maybe it’s worth saying is that right now you work at Ahrefs for seven years.
At the beginning when Ahrefs pick OCaml or Igor, our CTO came with OCaml in the back, there were not many companies working on- using it, using OCaml. Now we have Tezos, Tarides, Ahrefs of course, LexiFi, Bloomberg, BeSport. Many companies that have- even some of them have their own forks of OCaml that they are experimenting and deploying it or whatever. Seven years ago, do you think it’s a risky decision? The second question is how can you convince your boss about using OCaml?
Louis: [00:28:35] For sure, I think picking OCaml at the time was a risky choice because who do you hire? It’s like there were five OCaml developers. In Paris, you can find people. In Paris, you can find students. You go to the OCaml meetup and socialize and you can more or less build a company, which is what the previous company I was in called Cryptosense was doing. This is how BeSport came to life. BeSport just picked a few people around Vincent Balat and then you meet people. You steal one or two person from the OCaml meetup and you tell them, “Oh, join my company,” and now you have enough people to push a project forward. How do you do this from another country? Even today, I think it’s not an easy choice.
David: [00:29:35] Somehow risky, yes. That’s true.
Louis: [00:29:38] Today, you can hire, but even if you have, I don’t know, 2,000 packages on opam, the tooling is still- the libraries are not, there are not libraries for everything like you have in some other languages.
David: [00:30:00] Right. It’s big enough, but it’s not populated with everything.
Louis: [00:30:07] I don’t know if we have full support of GRPC. I’m not sure that we have complete support of http2 or 3. It’s not that small, but many things like this. I would say, today I would say it’s a risk. How would I convince my boss to move to OCaml? I would —
David: [00:30:34] Would you do it? Maybe you would not do it. Maybe you say, “It’s fine, we can do with whatever,” with Java you said that you enjoy the Java meetup, then you join your company writing Java. Would you be happy writing Java? Would you be fine? Or you would say “Oh, OCaml here makes sense, let’s try to change it.” How would you do it?
Louis: [00:30:57] I think if I was in a small company, it would definitely make sense to use OCaml. It’s interesting because in a small company you could say all the Java tooling has more value than in a big company, but at the same time you have less hands. You need to be more productive per person and you have less time for maintenance, and those are two things for which OCaml is very strong. You can write few lines of code that do many things, so it’s very expressive. At the same time, it’s solid enough that when you write your code, you can launch it in prod and you can leave it there for some time and hopefully nothing breaks.
The language is stable, the compiler is stable, so there will be no big surprises. I think that’s very valuable, and then you compare, what are the alternatives today? Rust is incredibly hard. It’s very, very hard language to use. You can do fancy stuff, you have incredible community but it’s a super hard language to use. You have what, Python, but then you are losing all the type safety. You have Go, which is a bit in between those. You have a fast Python I would say. Then you have Java. Java which has a huge community, and is a fast language.
In a way I think OCaml is closer to Java. It’s one easy language to use, solid, no surprises. The feature set is not incredible but it’s working well enough and you can do more or less what you want with it. You can do work in the back end, work in the front end, it’s approachable. To me it’s a replacement to Java. It’s a light Java.
David: [00:33:04] I’m mostly front-end. Now I’m doing some back-end stuff but I mostly am experienced from front-end. You are experienced from back-end of course and when I’m talking to back-end persons from OCaml, every time I talk with a back-end person who only writes OCaml they mention then the runtime. From the front-end, it’s a problem that I have never, ever thought. I know that the problem exists because I studied computer science and all these things, but it’s something that in the front-end I never think about it.
How could you describe to me that- I know a little bit about the memory presentation and about the stack, the heap, how memory works, even the O(n) notation, O big notation. How can you describe the runtime of OCaml, from someone who doesn’t know much about runtimes, so has nothing else to compare, rather than notes, for example. That’s my experience.
Louis: [00:34:08] Yes, I’m not an expert either, but it’s an interesting point, actually, because if you go on, for example, the real-world OCaml, there is a whole chapter on the runtime. I think it’s important for the OCaml people because of their background. We have those unixy people, so they have experience with C before and because in C you need to know what is a representation in memory of everything you manipulate, they took that from C and bring it to OCaml. Those people, they like to know, when I have an integer, it’s going to be nowadays, 64 bits.
David: [00:34:56] 63 right? That’s the —
Louis: [00:34:59] Yes, one bits for the right GC, and then we have 63 bits for the value.
David: [00:35:05] Right. Yes, people love the runtime. I think it’s like those things when — You guys started talking about the front-end. For me, I love CSS. I can talk all the time about CSS, but if you never have experience with a language or with designing the UI, CSS means nothing. You understand what they are saying because the thing makes sense, but semantically it doesn’t. When you talk about the run time at the beginning, for me it felt like I have never, ever thought of this.
Louis: [00:35:41] I guess it’s two sides. There is the technical side, how it’s actually implemented that when you allocate a value, where do you put it in memory? What is the representation of that value in memory? For example, we said that the int are 63 bits actually, that when you allocate the value, you allocate by words in OCaml. You have one word, for example, if you allocate the values that is on the heap, you have potentially two words. You have one word, which is a pointer to the actual value, and then the values, which is like a number of words afterwards.
You have the GC, so when is it triggered? Actually, the GC can be running every time you can allocate a value which means that you can write code that will not trigger the GC. It means you can write code that is very fast because there will be no interruption, and I think that’s critical for companies like Jane Street. Then yes, the other side is the runtime from a user perspective. I see it two way. I see one way that it’s like no one knows about the runtime because it’s very, very simple in OCaml. You don’t need to deal with the runtime very often.
You just know that you pass values by reference, so you don’t make many copies, and then the GC is fairly fast and will not stop for too long. That’s probably what 99% of the normal OCaml people know about the runtime. Then an interesting fact that comes with that is that the OCaml compiler is bad by modern standards, that it’s not doing any kind of optimization or very little optimization, yet the native code is fairly fast. The native code that is generated for an OCaml program is fairly fast. I think if you look at the benchmark it’s not too far away from C++, which is surprising, and it means that the language is pushing you to write code that by default is fairly efficient.
David: [00:38:06] That’s exactly my experience.
Louis: [00:38:09] The types that are offered and the functions, the APIs that are offered, somehow allow you to write code that is not too, too bad. I think it’s a miracle, but it’s an interesting one.
David: [00:38:23] Yes, that’s exactly my experience. At Ahrefs, the formula of the Coca-Cola of Ahrefs is like the crawler, the thing that navigates the internet and saves data. After that, we have storage and all of these pieces that are complex. What can you explain about the secret sauce of Ahrefs? What are they from the outside? Many people would never, ever write a crawler or a very dummy one, but for one that indexes 9 billion pages, 1 trillion? I don’t know the numbers but insane amount of numbers. What can you explain?
Louis: [00:39:10] I guess the first question is what is a crawler?
David: [00:39:13] Yes, yes, because you read the webpage, you scrap a webpage, that’s fairly simple. You can do it in any language, but then what do you extract about this page, and more importantly, how you navigate to the next one. I think that these are the two main questions.
Louis: [00:39:35] What you extract, depends. Ahrefs, we care about the links. What is Ahrefs building is more or less a map of the internet. The crawler is running all the time. It’s downloading, I don’t know, like 4 million pages per minute or something like this. There is a counter. Every minute we crawl 5 million pages. We have been talking for 40 minutes. You can count how many pages we have downloaded in a period of time. We download those pages and then we extract the links. That is the main information we care about. This is not the only information.
First is how do you parse HTML and how broken is HTML on the internet? This is horrible. The internet is broken. You have to extract all the links in a page and then you have to store all those links. When you store links, because — What is a crawler exactly? Where does it start and where does it end? Is it only the part that is downloading the html? Or is it actually the parsing too, and it’s influencing how you are storing your data, because — Let’s say you download a page and you have a 100 links in it, you do at least two things with those 100 links that you want to reuse them in your scheduler to decide what do I crawl next.
You also want to update counters, because you want to update your map of the internet. You downloaded a page, you know that there are links and you want to update the map. How do you update the map, because you have a 100 new links? What do you do? You update a 100 small counters, a 100 small integers. Then can you do it 5 million times per minute? Then can you do it in many direction, because it’s a graph.
David: [00:41:48] You would loop. If you don’t do it properly, you would loop forever.
Louis: [00:41:55] You have links between pages, but then you want to also count links between domains and you want to count the links inside the domain. Then how do you decide it’s an interesting link or not? Then when you index a link, what do you index? You need to index the link itself, but you want to index the text that is attached to the link, maybe the paragraph that is around that specific link. You could look where it is in the page. Is it visible or not? You have — It’s an open question.
That’s an interesting question, because there is no one that can say, “I’m doing a crawler and this is the right way to do it.” Even big companies like Google, they make tradeoffs. They decide, “We do it in one way.” Then they gather information they can gather. They cannot download every page on the internet all the time. They cannot download and process stuff fast enough. There is more content that is created than content that can be downloaded.
David: [00:43:00] It’s interesting, because if you think about fixing a bug on the crawler, it’s usually when you have a database, you can run migrations or you can get out data. You can store data broken or whatever. You can fix it. If you have the history of internet, that’s another source of data. It is life. I don’t know the right metaphor, but it’s — If you have to fix a bug on the crawler, that means that you stored information wrongly. That can affect the next version of your map, because it’s not only a map, it’s a map and a timeline. You can just look it up. It’s an archive as well. I think internet archives, they don’t have a crawler. I think they don’t have a crawler.
It’s the idea of — You can improve the crawler. Something that you didn’t look before, now you are going to look it up now. I don’t know, when — I think at some point we — At the beginning, either we started indexing, I think videos was — I don’t remember. Some media, I don’t know. That, of course, blowed up immensely, everything- they complicated everything.
Louis: [00:44:14] Yes. That’s an interesting question. Actually, Because, it is right that your database is very big so you cannot just migrate stuff. The big data page says we have 170 trillion rows in the database, so we cannot just push this to somewhere else.
David: [00:44:35] First of all, what technology is that running on?
Louis: [00:44:40] I think that’s a combination of different technologies. That will be a ClickHouse and then some internal database. Custom stuff.
David: [00:44:52] At Ahrefs, correct me if I’m wrong, we like to build our own things mostly. When I have it in other companies, you would use Sentry for reporting, or you would use PagerDuty for live crashing, or you would use whatever tool that you- or a web server, like a framework that runs your server. I think we implemented all of this by ourselves. That sounds both crazy from the outside, but when you join Ahrefs, if you ever join the company, you understand perfectly why has it been done like that. Yes, we have our own database. It’s scary.
Louis: [00:45:41] It’s not completely our own database, it’s more like a wrapper around existing database. It’s partially because we have no choice. The problem is large enough that you don’t have a ready made solution. Google was like this for a very long time. They had MySQL, I think that they used very extensively MySQL and it’s just that they used it in a way that was working for them. They don’t have a giant MySQL database, but probably they just sharded the problem.
They have one small database per server and they have a smart way to send the tasks to the right server to retrieve the data they want. Because you have to build on top of something, we are a small company. The total number of employees, I don’t know, it’s 100 plus now, but the back-end team is still 15 people or something like this. We don’t have too many hands.
David: [00:46:43] Yes. That’s insane.
Louis: [00:46:47] You ask what you do when there is a bug in the crawler and it affects how you conceive the programs because you know that something will run forever. The strategy becomes, I don’t want to fix bug by hands. It’s, you have an auto healing index. You crawl a page for the first time, and let’s say you make a mistake. The number of links you counted is off by one. You know it was like this for three days because you deployed, it was broken. Three days later, you notice it, and you cannot go back in time. It’s already too late.
Instead, what you do is that you fix your crawler. The way you store the data, you make sure that the next time you crawl the page, it overrides the previous version with something that is correct now. You have to have those auto healing processes, and you cannot attend to every small detail by hand, and the full rebuild of the index will be the last resort. Only if you have absolutely —
David: [00:48:01] Did that ever happen?
Louis: [00:48:06] It partially happened. Not everything, but there are things that were rebuilt once in a while. We were storing two things because we download pages, we download the HTML that we store, and then we have two counters. We have the counters we extract from the page. Let’s say you have one link that you see twice in a page. You have this link and the number two attached to it, and then you have diff. You store diff, let’s say, because you downloaded that page that belongs to the domain ahrefs.com. Now you see that that specific URL, for example, has three links that were not present before.
You store somewhere plus three, and later on you will aggregate all those plus three, plus one, minus one together. There are two different things. You have the absolute numbers and then you have those diffs. Once in a while, we have a bug that we didn’t compute the diff correctly. Then we will rebuild the diff from scratch. We will go back to those absolute numbers, process them altogether and then restore it. Then when it happens, it can take a month, but it hasn’t been done in a long time. It’s a long process.
David: [00:49:28] Right. That’s interesting.
Louis: [00:49:32] This is where OCaml is shining, too, because it’s very easy to have multiple versions of the same type, for example. If you store data, with a version number in the database, you have a variant.
David: [00:49:48] Yes, you treat it differently or?
Louis: [00:49:50] It’s fairly automatic and- yes.
David: [00:49:59] Yes, as well we have diffing on HTML. One of the big features that we did, I think that was last year, that we have diffing for the content of the page, or the diffing of links, we have as well diffing of content. That’s very good.
Louis: [00:50:18] We have a lot of small funny features. We are one of the first company after Google, obviously, to render pages at scale. We have hundreds of servers running chrome, and as much as possible, when we download the HTML of a page, which is the raw HTML, then we will put it in Chrome, let it run for a while and then get the rendered version of that. Which is incredibly expensive time-wise, because it’s much harder work than just downloading the HTML. We couldn’t do this if there was no project like Chrome that would be open source and usable for free. We are standing on the shoulders of giants for this.
David: [00:51:08] Imagine trying to create a web engine just to see a page from the server. That’s very good. What’s the favorite part of working at Ahrefs?
Louis: [00:51:26] To me, is the people. I’m not a SEO expert, and I’m not a SEO fan either. I didn’t join Ahrefs because I love to study the internet, that was not my goal, and I’m not a marketing person, so I don’t have a big use for SEO by myself. At first when I joined, the technical challenge was fun, but nowadays to me, the value is more the people. You get to meet smart people who work on complicated projects. I spend a lot of time dealing with interns, for example, which is super gratifying, I feel. I try to spend a good amount of time sharing with other people, working on the tooling or stuff like this. I really like that part, you can see the influence you have on other people when you make their life easier.
David: [00:52:32] That’s good. What’s your favorite part of OCaml?
Louis: [00:52:37] Of OCaml?
David: [00:52:38] Yes. You can say the people.
Louis: [00:52:41] When it compiles, it works. That’s the key point. Unlike Go, we have some types.
[00:52:41] [laughter]
Louis: [00:52:59] If we are a bit serious, maybe not the language itself, but the LSP is super, super good nowadays. It’s definitely a very good experience. We have to thank Tarides for all the work they are doing on the tooling over the past three years now, because it’s crazy.
David: [00:53:21] I think Tarides is carrying most of the boring work. Not boring work, but work that is always hidden. That you don’t get any fame, but you will only get the trash. When the toolings don’t work, you complain, and when tooling works, you just don’t celebrate it. Tarides is behind, for sure. You have been going to ICFP, ICFP is international conference for functional programming, for quite some time. One of the verticals, or one of the parts of ICFP is OCaml.
Last year we outgrow our neighbors, our language neighbors, I think it was Scala, maybe, Haskell. I think we outgrow them. What do you think about the conference?
Louis: [00:54:20] Same thing, it’s amazing to go there and meet the people actually, because ICFP, it has multiple parts. The main track is a bit more academic. Even though some people who work at Ahrefs, they published there, but they were students when they did it. It’s a bit more academic. Then you have all the workshops that are a bit more approachable, at least for me, but you spend one week with smart people who are very excited by what they’re doing. This is the amazing part. Once a year, everyone is super happy to meet each other. This is very much a good experience, but it’s- about conferences, I think the ReasonML ones were very, very nice too.
Again, I’m a back-end person, but it was super cool to attend a conference on a different topic where people have different interests, and it was the early days of the language for people who were super interesting, the people who attended were curious and wanted to see something new. They had different ideas. I think that was super good.
David: [00:55:36] Yes, those conferences were very good. I haven’t attended any, actually, but yes, I heard Javi saying amazing things about them. Almost everybody who attended said good things. Why there’s no OCaml conference?
Louis: [00:56:00] This is a multifold answer, because it’s actually a question that was asked. There is this, how is it called, the OCaml Software Foundation, because if we can explain how OCaml, the management of OCaml is that —
David: [00:56:23] Please do. As core contributor of the code of conduct, please do.
Louis: [00:56:27] There is the core group of contributors for the language, and out of that before there was something called the OCaml Consortium, I think, where companies could pay few thousand USD a year and it will give them a license to use OCaml not as an open source project. You could get the compiler and do changes on it and you didn’t have to publish the changes again. It was also a way to just sponsor the OCaml development. They took it to a different level. They created this OCaml Software Foundation that is pushing some efforts around OCaml.
One question was, do we want to have an OCaml conference or do we want to have OCaml- maybe not conference, but smaller events but that could happen more often. Where will we put those events in the world? You need people with time, you need people with money, and you need to find the right place for the right people to attend. I think no one has all those resources, including the mental space to build fancy ideas on what to put in a conference. I cannot provide a definitive answer because I’m not the one deciding on all those things, but I think it’s a combination of all those that makes the ICFP the place to be.
David: [00:58:05] Right, because this year is on Seattle. Every year it changes the location.
Louis: [00:58:13] Yes.
David: [00:58:16] Last year we released we- I didn’t but yes, OCaml released multicore and effects or handling effects. We chatted a bit, a lot at work about this, and I think you said multicore was not something that needs to happen, but you are not very excited. On the contrary, you said the effects are a big deal. Thinking about the person that doesn’t know a bunch about what effects are, could you do a short summary and then explain why those are exciting?
Louis: [00:59:01] I’m not a specialist with effects either but to me, a parallel will be to talk about Rust. In Rust, you have those ways to, how is it called? Borrow checker. You have a way to know to who one value belongs. It heavily affects how you are writing code because then you need to architecture your code in a way that is safe. Do you know that, for example, that value can only be used by one bit of code at a time?
David: [00:59:45] Right. Otherwise, you would have crazy bugs. Data corruption
Louis: [00:59:56] That would be C. Rust came in and was provided this safety. That’s a bit the same idea in OCaml. It’s like you come with effects and I think it has many usages that I do not completely understand, but some of them allow us to change the way we do concurrent or parallel computations, and it makes it safe. Like the borrow checker makes the Rust code safe. This is definitely affecting the way you write code because now you have one more tool to express your ideas. I think this is definitely changing the way the language will be used.
While the multicore, it’s just in the background, it is happening, but this is not the tool. This is just a mean, so it’s like, how do we do fast computation? Do we need to split stuff on different cores and how do you do it? Either you fork or you do multicore. In a way, it could be completely hidden behind a magic API and I will not know if it’s fork or multicore, and it’ll be fine to me as a user. If you have something like the borrow checker in Rust, this is actually a language feature, and this is something I see day to day and it is affecting how I can think and what I can express.
David: [01:01:36] Right. I see, I see. Yes, because right now one of the features that Jane Street, the famous company that does the Wall Street and whatnot and pushes OCaml for the next level, they have a team working on the OCaml compiler, and one of the big fears that they want to work on, I think, they call it locality or local, global variables. Would that express, I have no idea about those rather than watching Stephen Dolan at the presentation on last ICFP, but would that allow some of the users of OCaml that they do care about the memory layout or the owner of the variables to express those different changes regarding using multicore?
Louis: [01:02:34] I don’t know exactly — My own — I mean, I have a light understanding of that. To me, I think it would be interesting even if there was no multicore, the stuff they’re doing local/global because we already had concurrency with lwt or stuff like this. It has benefits because you control your allocations too. You can decide what is allocated on the stack versus what is allocated on the heap. It can have big performance implication.
This is an exciting feature, but this is maybe where you see my C background that when I was in uni, the first year was just writing some C code and we had to rewrite Bash. We had our own version of Bash. We spent two months writing in Bash or stuff like this. We had to deal with many of the small like — You are launching a bunch of processes together and you have to manage your memory or whatever, or we had to rewrite malloc, so we —
David: [01:03:53] Okay.
Louis: [01:03:56] I know little bits about memory management and how to deal with pointers because I did those projects in the past. These local, global things seems appealing, but at the same time, it’s probably not critical. It’s not going to change the vast majority of the code that is written in general. All my small personal projects or even most of the code that is running at Ahrefs, performance is not key. I care more about the fact that the code is readable and stable rather than performance, I would say.
David: [01:04:42] Yes. Only in somewhere else. Yes, I see your point. Usually, code, for example, just like a web API were way, way fast enough. There’s no point to optimize the endpoints. Most of our endpoints I think we have 500 endpoints. That’s optimizing one by one or optimizing 10% of them, they would not change absolutely anything.
Louis: [01:05:10] We spend so much time doing queries to different databases or http query to gather whatever we need to gather before to answer a request. This is so expensive compared to what we do most of the time.
David: [01:05:28] Right. That’s true. That’s true. Why do you think Ahrefs is such a different company? When I have experience with the — It’s because of the culture maybe? Here we don’t have real management, we don’t have product owner. We don’t have many things that when you come from working on the SaaS companies that are from the culture of US maybe, or some Europe companies. In Ahrefs we don’t have anything like that. Can you say that it’s good or bad and why?
Louis: [01:06:07] It’s good and bad. There are definitely some downsides. Why it’s like this, is also because the company is young and small too. It’s what? 10 years old so it takes time. Every time you want to make a change company-wide, it probably takes two years to actually make change happen.
David: [01:06:33] Okay.
Louis: [01:06:35] This is not the only company with a structure that is not well defined.
David: [01:06:44] Right.
Louis: [01:06:44] What happens is that there is a structure, it’s just people don’t have the title because actually when you have been in the company for a long time, you own some bits of codes and there are people who are expert on the subject. Then there are people that you trust for something and people that you trust for something else. Even though there is no direct management, there are people taking decisions, so who is taking the decision, right?
David: [01:07:16] Right.
Louis: [01:07:17] It’s good to be flexible and it allows more or less anyone at some point to take a decision if they want to and if they dare to. The downside is that sometimes you don’t know if you can take the decision or not, and you don’t know who you should talk to and then there are some hidden politics because some products, some features there, they belong to someone. You don’t want to offend that person so you can’t go and touch this or stuff like this.
David: [01:07:51] Well, I need to interrupt here. I think you have been way too long at Ahrefs to realize what politics — What it means because in Ahrefs there’s literally zero politics or not politics, but battles or discussions for the sake of discussion, it’s nearly zero. I think that’s one of the things that at the beginning of like, are we not talking about this and somebody said no need to. It’s the culture of getting very direct and very technical focus.
I think when you work in a company that you can be weeks without knowing what to do or just months working on so many processes that are close to useless from your point of view or maybe very beneficial from an individual contributor, you feel like you are losing your time. In Ahrefs I don’t think I have been noticing a layer I thought I’m losing time because of the company it’s the other way around. Oh, my peer is asking me to implement something that needs to be done and I haven’t finished yet. That’s more the feeling of the work, right?
Louis: [01:09:09] I guess it’s not politics looking for power because there is no power to gain.
David: [01:09:16] Exactly.
Louis: [01:09:17] What do you want to own? There is nothing to own. You can try, but there is nothing to win at the end.
David: [01:09:26] Getting to the last questions now, but have you been following a little what Javi and Antonio and a little bit of myself having worked in Melange. What’s your opinion about Melange?
Louis: [01:09:43] I know what Melange is.
David: [01:09:46] Definitely.
Louis: [01:09:47] Okay. What do I think about Melange? Again, it’s a question that is hiding other questions. Let’s say technically, for example, this is pretty impressive. What the four of you have been able to do in a few months is amazing. Because just to give some context, it’s like moving — Okay, Melange was not super, super alive, six months ago. The project was moving but slowly. There was no Dune support, there was not much stuff happening. Then six months later, you have the whole Ahrefs front-end, which is like, hundreds of thousands of lines of code that are written by what? 30 people maybe now.
It’s completely moved to Melange. This is amazing. I’m able to compile all this code in one comment. I go in the repo, I do “make dev” and everything works.
David: [01:10:56] These and many more advances, but yes, that’s the part that it’s funny.
Louis: [01:11:04] Yes, it’s amazing. It automatically works and it didn’t break the experience of anyone so it’s compatible with what was bucklescript or rescript beforehand. It’s compatible with native code at the same time. It’s amazing. What do I think about the project? Another side of the question will be, was it the right thing to do to fork rescript? Or, is it the right way to do it? Is it good to have a fork of the compiler inside of Melange to achieve that project? I don’t have a strong opinion on it.
I don’t have enough experience. After all those years of seeing Reason and Bucklescript evolving, I believe that the experience of the end user, so the developer that is using these tools, is more important than the technical implementation. Is it the best way to do it? I don’t know. Does it give a good end user experience? Yes, then that was the right thing to do.
David: [01:12:21] On those tools, you would always prioritize the developer experience, rather than technical merits? How would you choose —
Louis: [01:12:33] As a user or as a developer of those tools?
David: [01:12:36] As a developer of those tools.
Louis: [01:12:39] As a developer of those tools, given the target, given what I see of how you build a community and it’s like the early days of Melange, I would prioritize user experience. I think, for example, all the efforts that have been put into making Dune work, I think the target was the user experience at the end. Because we couldn’t make it work another way. If we didn’t have this, I’m not sure that we would have moved to Melange, for example.
David: [01:13:19] I see.
Louis: [01:13:20] What’s the downside was that for example, this is not the fastest implementation there is. I think there is some many different calls to this Melange compiler that are not the fastest way to do it, but the UI is good so we still use it.
David: [01:13:44] What I would like to feature, knowing that at the start Bucklescript got born, even though they were like js_of_ocaml. Now, I think, eight or nine years past, Rescript got its own path, but then Melange is trying to again, be part of the OCaml to Javascript compilation, or Reason to Javascript compilation. How do you see the future? Because eventually, nobody wants to have two ways to Javascript.
Louis: [01:14:16] I’m not sure that’s true. Why would people not want many ways to do the same thing? It’s like if you look at other languages, actually, many of them have different ways to do the same thing. Why not OCaml? As long as the projects don’t die, it’s not like Melange is attacking jsoo or jsoo is attacking Melange. It’s like, people don’t hate each other. They are not fighting for users; I think the targets are a bit different.
David: [01:14:53] You would want different ways of combining to Javascript? Because the sane competition? That’s true-
Louis: [01:15:03] To me it’s not the sane competition. It’s more that I think it targets different audience. It tries to do different things. One example will be during one of the Reason conferences, we wanted to do a workshop and we wanted to show atdgen which is a tool we’re using a Ahrefs lots to parse and write JSON. It’s protobuf but for JSON.
David: [01:15:34] Yes, it would give us type safety from front end all the way down. Sorry, backend all the way down.
Louis: [01:15:43] Yes.
David: [01:15:43] Sorry, go on.
Louis: [01:15:46] You have as with protobuf or with Graphql too you have a definition, you have a file with type definitions and from the definition you derive OCaml code or Python code or TypeScript code. It supports multiple languages. To do so you need an atdgen binary. In the Reason conference, you have people using Linux, Windows, Mac, different version, whatever so how do you give a binary that everyone can use? In two minutes, I just went into the atdgen repo and I enabled js_of_ocaml compilation inside Dune and now my binary is actually JS file that I can run in node JS.
David: [01:16:34] Right.
Louis: [01:16:35] I don’t think that Melange aims to do that. Because then —
David: [01:16:41] I think that’s the magic. Yes, I agree.
Louis: [01:16:44] In Melange you will have one file per module or something like this, which means I will need to run through webpack or something like this later on.
David: [01:16:51] Yes, you could but you would face a few problems. Marshall for example, that it’s the encoding/decoding on bytes, that doesn’t work in Melange.
Louis: [01:17:01] Well, it doesn’t work in js_of_ocaml I think too.
David: [01:17:05] Yes, but I think you can stub it, right? I think you can —
Louis: [01:17:10] But I would say most of the time actually you don’t care because it’s corner cases, it’s just that the UI they provide is good enough for OCaml people and Melange, it provides the nice, what? FFI, for example, to interact with the JavaScript code. The way it outputs code is closer to the JavaScript way too; I would say so it’s easier to make webpack or other tools like this work together
David: [01:17:39] Yes, I agree that those are different targets. It just my point of view was more like, okay, js_of_ocaml the crazy thing is that you have entire project in OCaml. You add one line say in Dune compile to node JS please and then you have a single file that is compiled to JavaScript. That’s insane so if you have, for example, a compiler written in Menhir it’s a language to write compilers in OCaml, you can compile it to JavaScript in one line or any library, even drivers, even anything that you can imagine. That’s the valuable position or thing that gets people to try js_of_ocaml very fast. But on the contrary, the documentation is very bad.
It’s the classic OCaml project that you need to understand 50% of the project to even start it so that’s like — For people like me, I invest a lot of time trying js_of_ocaml and even try to write bindings to React and succeed but I did not succeed convincing people in Ahrefs, front end of Ahrefs to try js_of_ocaml. For me, that was the — That technology is not good enough for prime time or not good enough to convince my team, then yes, there’s no way to convince any other.
On the opposite, Melange fits together the low barrier to try and good documentation and at some point, it gets complex but the ease of experience I think it’s much better. But yes, you don’t have a one line — You need to meddle it a bit on building the integration with your front end or your pipeline but yes, once it is done, it works. But yes, you would never do that with atd. The experience in atdgen that’s not going to happen in Melange.
Louis: [01:19:41] It’s funny how you say it and it’s true that it’s easier. Many things in Melange are easier to experiment with and at the same time it’s more complicated. For example, in js_of_ocaml you have a clear separation between OCaml types and JavaScript types. String that is an OCaml string is a different type from JavaScript string.
David: [01:20:10] You have like a wrapper, right?
Louis: [01:20:12] It’s very explicit and it’s good for the OCaml person because then you know when this is a part of the language you are comfortable with and then when it starts with JS, it’s okay, be careful because you don’t know what you are doing. This is easy and in js_of_ocaml. Because it’s very easy. You see JS dot and then you know now I have a JavaScript value. In Melange it’s your string is what? And you have to deal with the encoding. What is the actual encoding of a string in Ocaml?
David: [01:20:57] Do you remember that I said that every time that I’ll talk with a backend person, they always mention the runtime. Exactly that moment. You always think about the runtime.
Louis: [01:21:06] Actually, I’m not sure.
David: [01:21:08] It’s not the runtime itself, but the encoding. In Melange for example, of course, all the types not of course, but all the types that you have in language are the same representation as a JavaScript value. For example, a string is in a string, integration is a number, float is a number and so on and so forth. Variant is an object; a record is an object. Melange maps perfectly or as good as possible to JavaScript values. It’s cool that you said that when every time that you work with js_of_ocaml, once you see JS dot, whatever this is the namespace and you know that you’re treating with things that come from the client.
For example, that’s a barrier for people that tried rescript or tried Melange in the first place because they don’t understand why do I need a wrapper? Why do we need a generic for at type that already have? Because it’s the mentality of why do I need to care about the runtime?
Louis: [01:22:17] Yes, basically you pay a cost but at a different time, like in js_of_ocaml, you pay the cost very early because as soon as you write code you need to make the difference between the two words. In Melange you will only pay the cost if you write FFI and you need to care about the representation. It’s if there is a string with something weird in it, you don’t know the encoding of the string, for example, then you need to be careful.
The experience by default is much easier. It’s just that when you are dealing with the boundaries then things can be a bit more implicit and probably you need to know the language better to do things the right way. It’s easier and it’s actually more complicated in some bits.
David: [01:23:08] Yes, I think if you look now, js_of_ocaml and Melange are very drawn line. You can draw a line between the tradeoffs. One side is very clear, one side is very clear. Now, I would say that I’m comfortable saying that both are balanced for the users, even rescript now. For me now, I have a feeling the three of projects are in the right column. You can classify them perfectly now. If you get into, “Oh, I want to try this ML or like OCaml, whatever language as a whole,” you can choose — Based on your team or your decision. You can choose clearly one another.
Louis: [01:23:57] Yes. Actually, you said you couldn’t sell js_of_ocaml to Ahrefs, but we can probably talk a bit about what was the discussion, what happened, because Javi and you, you actually tried to do something so that it could happen. You work on the React bindings and then you try to show that it could work. In a way, I think that js_of_ocaml, it could fit what we do because we don’t depend on a lot of external code. One very interesting thing in Melange is that the FFI is very good. It’s easy, convenient, to interface with other existing JavaScript libraries.
In Ahrefs, we have bindings to what, React, and then maybe one or two library to deal with the timestamps and charts. We don’t have millions of bindings. We have maybe five big libraries we have bindings for, and then a bunch of smaller stuff. We don’t bind to so many things and we don’t need FFI that is amazing. It’s not a priority. js_of_ocaml could have worked.
David: [01:25:14] Could have worked. I agree.
Louis: [01:25:16] The fact that even in this perfect setup for js_of_ocaml it fails is interesting. You find the right company with many OCaml people, many people who understand js_of_ocaml, and you don’t need one of the best features of Melange and still, this is not actually the tool that won at the end.
David: [01:25:42] Yes, that’s true. The experience, I think that’s exactly what you said, it could work, theoretically if you look at the direct from the outside or even if you look at far from the front end, it makes a lot of sense. Once we were working on this, I was working on this middle-end team, before it was not called middle-end. I was working on the middle-end, and most of my assumptions were like, “It’s going to work perfectly.”
Because of what you said, right? Then when we try to — How can we write React, we are married to React. I think we like the model of components. We like the model of data; we like the composition. We’re not going to change React. Let’s bind it to React, so we create the same PPX and the same library to React. I think that was how Javi started and then we end up finishing.
did the emotion binding, so I know the CSS, everything worked and we felt like js_of_ocaml was very mature, but there were a few problems that you could not solve easily at the time. At the time js_of_ocaml didn’t have Unicode support. Now they have some Unicode support or the parsing, I haven’t followed that closely, but you would need another library to run to get the Unicode support that in Melange or Bucklescript at the time was natively. That was an issue. The other issue or biggest issue that you can’t bypass is that js_of_ocaml, you compile it in one file, one gigantic file.
Incremental migrations were very hard or very difficult to iterate over time. You could migrate parts of the app, but then you would need to compile everything in both, have two duplicated apps. It was definitely not — The migration plan was impossible. We could try. I think we tried in one of the small apps, I think we could try wordcount, is one of the verticals we have at Ahrefs, with js_of_ocaml, and once we were trying those, we find the wrapper, it was very hard to sell.
The wrapper is like the Js.t that we call it in Recript, in js_of_ocaml I think it’s JS.object. It’s unsafe. You have JS.unsafe. There are many, yes, many constructions you can track with JavaScript differently from what we do with the bindings. That part was — With these three things that I said Rusty, which is one of let’s say the only Tech Lead at Ahrefs, like the only person that — He’s the CTO in the frontend, how I call it.
He was the person who we would need to convince to migrate to the frontend. He was definitely not on board with the idea. I think that’s the main reason. He would chat with our people and people would say, “Yes, fine, if Javi and David are happy, then we are all happy,” but even though we migrate one small app, the experience was worse. The user experience of iterating over React components was worse or even the data was worse because you had this wrapper.
Louis: [01:29:23] There were too honest in the way they named functions in the API. For example, all those unsafe functions, they exist in every FFI, it’s just not called unsafe, but because it’s called unsafe, people are like, “They’re not going to use this, you are not supposed to use it.” Yes, you’re supposed to use it. Just be careful when you do it.
David: [01:29:47] I think you explain to me that anecdote, is that somebody asked Xavier Leroy the creator, the author of OCaml, they ask, “What do you think about Objec.magic?” Right? Object.magic is the method of OCaml that you can, like unsafe, coerce any variable, right? You can light the typechecker and say, “Trust me, this is whatever, an array and it’s a list or whatever”. His answer was, it is like when you are working in the street, would you inject — How is that called? I don’t remember the thing, but would you become a junkie?
You get a syringe, I don’t know how to say in English, but would you inject some random thing on the street? That’s not part of the language. I think you’re explained me the anecdote, or maybe it’s Javi, How do you see the purity of OCaml? Do you think that the OCaml is very pure or has some pragmatism on safety? Because of course it’s type safe, of course, the compiler when it compiles it works, but you can bypass it from time to time. What’s your opinion?
Louis: [01:31:10] I don’t think it’s pure in any way, shape, or form.
David: [01:31:17] You can write pure code, right?
Louis: [01:31:20] Yes. You can write pure code. But for example, you have exceptions that are very pregnant, that are everywhere and you don’t have any way to know if a function can raise an exception or not.
David: [01:31:37] Right.
Louis: [01:31:38] Okay, it depends what program you write, but basic things, you run your program, like a CLI that is running — I don’t know, downloading something and you press control C like you want to stop your program. There is — It’s a signal, and in OCaml it’ll raise an exception that you need to — You can catch and you can do something with it, right? At any point in time, the user of your CLI can come and interrupt the program, right? Which means at any point in your program, you need to be able to deal with this interruption.
David: [01:32:18] Right.
Louis: [01:32:19] It’s like as soon as you have these where is the purity, what is — You have no good way to protect yourself against all these issues. At the same time, I’m probably biased because I have been using the language for long. It provides you what is good enough. There was some improvements because, I don’t know if you remember, but at some point, the strings were mutable in OCaml.
David: [01:32:51] Yes.
Louis: [01:32:53] By defaults, the strings were actually what is called Bytes nowadays. It has been a big change. People had to fight to turn Bytes into string, because it was breaking code, obviously. There was more mutability. It was not as pure as it is nowadays, I would say that the balance is not too bad. Could it be more? Probably. There are some things that we can’t really express in OCaml, like ownership of a value.
Like you open connection to a database, you have a handler or something like this that you want to use only at one point in time and you don’t want to share. You have no way to express it. Then you can’t really protect yourself against the steal. The code can take that value, put it in a global reference, and it can be suddenly reused elsewhere. This is where, for example, the local/global stuff —
David: [01:34:06] Yes, solve exactly that issue.
Louis: [01:34:09] Yes. This kind of issue. Is it a problem? Yes. Is it a problem that we face at work? Yes. For example, we see like — We have one problem where people can open the connection to a DB using one of those — A common pattern in the ocaml to do like “with_db” for example. Then you pass a continuation, you pass a function, and then this with_db function will create a DB handler and pass it to your function later on.
Inside your function, you can do one more with_db. This is something that you probably want to forbid because you don’t want to open connections after connection after connection when there is already one available.
David: [01:34:57] Right.
Louis: [01:35:00] For now, how do you fix this? This is an actual problem and you have no good solution. But maybe you write different code than I do. You write code that is in the browser or just behind the browser so maybe you have different views. You have to deal with more mutability than I do, for example the whole DOM, before React. Yes, but before React no one assumed that anything was immutable in a browser. Everything could be changed at any point in time.
David: [01:35:43] Yes. That’s why in the browser many APIs were pushing for observables, right? You accept mutability into all your values and then you say any value can change in any time and you need to subscribe to — Listen to the changes or not and that’s the trend of — I think that was one of the biggest inclusions of ES4 that didn’t get published and they tried with ES5 and they didn’t get to the language neither that are like these observables concept. I think they come from React JS and they come from reactive programming from, I don’t know, 30 years ago where sometimes reactive is very useful. Before React, I would say that not many people did — The immutability was not part of their fashion of writing code.
We are very far from those problems. We do immutability in a few places, for example, we have a global theme, a CSS theme, right? You can have a dark or light theme. We interact with the browser directly. We opt out from React to do that because the performance is better. You can load that at the beginning, you can then allow React later. But the way it’s just very self-contained, right? You will never want to write your data reactive.
Maybe you want, but for example, for Ahrefs it doesn’t make any sense because our data is you have tabular data that never changes on your session, right? It’s not live data. It’s like you open a report and the report is the moment time that you request. There’s no live thing. Nothing is very reactive in nature so yes, for us it’s just like a perfect sense.
Louis: [01:37:41] You would be happy with more purity?
David: [01:37:45] Would we be happy with more purity? No, I think —
Louis: [01:37:49] Would you wish to have a language that is closer to Haskell that is like —
David: [01:37:54] No, I don’t think so. I think no, because purity makes — Purity in some places makes your life so much better, right? But often you want the tools to be pure so like libraries that you create or you consume need to be pure but your application needs to do all sort of things, right? Your application or when you are a product engineer, you want to just ship fast and if something gets you in your way and you store it globally and deal with it later or store it globally and be safe and then forget about it.
You need to do things perfectly and draw the line and architect things that slows you down insanely. I think the line — OCaml is very well position where you can opt out, do your life easy and then move back and run fast. But yes, my tools to be pure or libraries that I’m using or even — I know I’m working on styled-ppx so making types safe, like your styles. I think that’s something that I’ve been pushing but yes, you want that tool to be type safe.
You don’t want to do all your things on your app perfectly, to demand it perfectly mostly because on the web, everything is changing all the time. On the backend it’s a little bit different but on the web, iterations are just much more common than in the backend
Louis: [01:39:31] I find it interesting that everyone is pushing for immutable stuff. At least my impression is that in the front end React maybe didn’t create this trend but made it popular. My understanding is that you deal with the DOM as an immutable object. You never manipulate the DOM directly anymore. You do it through React. You have an immutable object, more or less, which goes against many things that happened, historically in a browser, the way the DOM is implemented is completely not like this. It has some interesting benefits.
You can have any extension in your browser that are changing part of your page. I’m using one daily. I’m using Dashlane to store my passwords. It does stuff for — If there is an input field, it’s creating a popup and I can click, input my password in that specific field.
To do this, it has to inject HTML in the page actually. But it breaks. Some apps are crashing because of this. Some apps, some websites, they’re not crashing. They will just see that there is a change coming from my extension and they will just discard it and rerender without my stuff.
It goes against many things that happened for 20 years, more or less. You have to make both of those worlds still somehow work together.
David: [01:41:18] I think React did — I think not even React, Meta did that all the time. They pushed for a solution that is way better in some areas but destroys previous effort insanely. For example, with GraphQL, I think it’s happened the same. They say, “You’re going to have one endpoint. It’s going to be through POST.” You would call this endpoint all the time, which goes against completely about REST what we were doing before.
Of course, with all the tradeoffs, if you go 10 times — 10 years back and you say to a person, “No, we call all the time same endpoint.” You will say, “You guys are stupid.”
Louis: [01:41:58] RESTful was a trend.
David: [01:42:00] Exactly. The RESTful, you will need to add the link to go to the next resource. Of course, all the people would scream at you. Similarly, it happens now with server components. I don’t know if you are following the thing. Again, they are pushing for a new concept that they have mined in their business and works well. The rest of the people are like, “No, that’s just insanity.” I think React, the first concept is you — The insert and update are the same operations.
There’s no create the DOM and then update the DOM. It’s always like, “Do the thing.” It’s just rerender. Just because they push for that approach and they delay, of course, the first load is going to be slower. You don’t have serialization. Then later updates are going to be faster.
Louis: [01:42:58] Actually, even the later update are slower, because you need React to do this diff between the two version and to only update the relevant part of the DOM. React is doing what the browser was actually doing. You are duplicating the work and you are doing it in JavaScript, which is slow. The browser was doing it in a very optimized C++ code
David: [01:43:26] Fair point, but the DOM is fast enough. I think I read a lot of articles about anti-React that the DOM is fast enough. I think that’s — These benchmarks are nonsense. Those benchmarks — Even the benchmarks that — I would call it micro-benchmarks. Even microbench like — I don’t know, work faster, implement some charting library mutable to DOM and using whatever, Vanilla JavaScript or using React. Of course, you can outperform React but at what cost.
The cost of creating two charts, two components of a chart, the API nicely, blah blah blah blah rather than mutating the DOM all the time. That’s super expensive. When you’re working, for example, for Ahrefs, I think we have — I don’t know, 2 million lines of code in reason. I don’t know, 5,000 components. Some insane amount of number of components. If you do that in mutable or maybe not mutable but maybe just going to DOM and listening to DOM and hoping that everybody is a good citizen. It’s just you would slow down development so hard that it doesn’t make any sense.
I think React draw this line where virtual DOM is like if you know how to create the structures, know how to trigger the renders, I think can be as good as the DOM, of course. In general terms, I think it’s good enough. I think the balance is very OCamly. [laughs] You know that Jordan was behind, when — Jordan is an OCamler that knows this balance, that —
Louis: [01:45:23] It’s funny, because you could say that for example Facebook has enough resources to make it work, right? They could have decided it is going to be a more troublesome for our developers, but we are going to offer a faster experience for the customers, the people actually visiting the website. But even them with their infinite resources, they decided to go in a different direction. Is it because it’s a tech company? I feel that some big tech company, they run the way they do, because they are led by technical people, so they can make technical choices instead of business choices sometimes.
David: [01:46:08] React is that, exactly that case. I think I saw the documentary about React, and it’s more the idea just spreaded everywhere. I think they have that competing library; I don’t know how, I think it’s called Jacks or something. I don’t the name, but they have a competing library that was written with PHP and XML, and the whole stack on meta back in the days. The idea of React spreads everywhere. The point that you made before of developer experience leads everything in the early days. I think that it just applied exponentially, because at some point they released publicly, everybody hated JSX. Then after one year it was the most famous library used. Then from now on, the monopoly went for, I don’t know, six, four years, I don’t know. So many years that now everybody has the component model, the hooks, the state. It spread the idea everywhere. It’s interesting, but I think it’s just like [unintelligible 01:47:11] , so.
Louis: [01:47:13] How smart do you need to be to Jordan and be correct about React was the right thing to do, and to do it properly, and then Reason was the right thing to do, and to do it properly?
David: [01:47:25] How smart need to do. I don’t know. Uncountable, I would say. Hard to quantify smartness. It’s hard to quantify smartness, but I think it’s even harder when you look at what Jordan has been doing. I think Jordan is the kind of person when you speak with him, he talks, or he says things that doesn’t make sense at the beginning. It’s his way of thinking. He’s thinking three, five years ahead, and when he explains the idea to you, you are like, “I got the sense that I didn’t understand anything.” After a few months you start saying, “Oh, right, it made sense.” I think everybody on the React team only says how brilliant Jordan is. So, yes.
Louis: [01:48:18] It’s interesting that you interviewed Rudi, the author of Dune, and he said that even him, for example, originally when he saw the Reason syntax, he was like, “meh,” like, “What is this thing?” Like, “Yet again?” He say, “Yes, at the end it was right to make it more approachable.” This was from a user experience perspective. It’s a clear benefit.
David: [01:48:44] Yes. I love that interview, because Rudi said exactly that, like, “Oh, at the beginning Reason felt like a toy, but then we were doing tooling for OCaml, and the language and a lot of work on the actual language. Reason was the thing that bring more people on OCaml, than we never, ever did. Even though it’s not a competing language, even though the person that created has so much power into the frontend people, even that the number of people that got into OCaml community, it was bigger than any other effort that we made. [laughs] Which for me is super funny at the end of the day, because most of us came from the JavaScript and end up doing OCaml and mixing everything. That was the idea.
Louis: [01:49:40] It’s funny how you need a little bit of luck for all those things to work. You need, for example, Rudi to decide early on, “Okay, I don’t really trust this thing, but I still I’m a good citizen, so I will add the support inside Dune”
David: [01:49:56] Yes. That’s very noble.
Louis: [01:49:58] It’s like if you don’t have those people who are able to compute this is maybe good or maybe bad, and are able to balance their opinion, versus the community thing. They have to do it early enough, at the right time. It’s interesting that somehow —
David: [01:50:24] Of course, not what everything Jordan says is correct, I think in the sense of, of course, he created stuff that was definitely not on shape or not on the area of success of React, of course. I think he created React and then React native. Of course, they both are insanely successful. Reason I would call it successful as well, but actually, push the idea of Esy. Esy is the package manager that is still somehow used, and some people love it. Even myself, I have a lot of respect for Esy, and use it from time to time. That you can consume JavaScript libraries, npm packages as well as OPAM packages.
This project has been suffering for long, that it’s definitely not the right solution, or at least, it didn’t create these ideas, this sudden idea to the rest of people to continue pushing for it.
Louis: [01:51:27] This is one of those tools where I think the technical implementation was good, but the UI was not great. The output is just not nice, for example. You run it, and then it displays some-
David: [01:51:44] You mean, the actual UI, the CLI?
Louis: [01:51:46] Yes, because opam, which is not the most fancy tool ever, but still when you opam install, it has some colors. It doesn’t display one line production. It’s some kind of somehow clean output that Esy doesn’t have. You had to learn this weird JSON syntax to put your package, and it outputs ugly text after that. The idea was very good, but the UI was not completely working.
David: [01:52:24] I think Esy has some, people call it state-of-the-art ideas, the end goal of our package manager, what do you want to do, or we want to use. The efforts of maintaining the overrides or being on top of all the libraries or even compiles Esy, there’s a lot of maintenance that needs to get done. At some point, we have a team of, I think, six, seven persons working on it, and that experience was very good, but from when Reason got a little bit lost, this team, those people —
Of course, when the blockchain companies started hiring all of them to work for Web3 and paying them insanely amount of money, then the project got a little bit carried over, got a little bit less maintenance then is likely in a stale mode that you can use, but you could get not as good as opam.
Louis: [01:53:35] This exactly why there is no Rust code inside Ahrefs, because all the developers got stolen by the blockchain companies.
David: [01:53:45] That’s fair. That’s fair. I think, Louis, we are running out of time. For me is daytime, I can do stuff, but for you is definitely night time. I can work, talk with you for hours and hours, but I think the show is reaching to a point to finish. It was a pleasure to have you, of course.
Louis: [01:54:07] It’s a pleasure.
David: [01:54:09] If somebody attends to ICFP, please go to Louis, I think he’s the party manager, and as well, a person very interesting to talk to. Please, bother him. I think he’ll be in Seattle on September.
Louis: [01:54:26] Yes, Seattle, September 4th to 9th, I think, something like that. It will be online too, this year. I think it will be online and for free. All the talks, at least all the ML, or maybe not ML, but the OCaml workshop will be online of free. There is no need to travel all the way to Seattle to see the talks, at least to see the OCaml workshop.
David: [01:54:52] Makes sense. In this era of internet, I think that makes sense. Cool. Thanks everybody for being here. You’re having a little bit late day, but that was perfect. Thanks, Louis, to spend time with us.
Louis: [01:55:07] Thank for having me. That was fun.
David: [01:55:10] See you guys.
[01:55:13] [END OF AUDIO]
EmelleTV: Talking with Louis Roché about OCaml and Ahrefs was originally published in Ahrefs on Medium, where people are continuing the conversation by highlighting and responding to this story.
HideOxidizing OCaml: Rust-Style Ownership — Jane Street, Jun 21, 2023
OCaml with Jane Street extensions is available from our public opam repo. Only a slice of the features described in this series are currently implemented.
Florian's OCaml compiler weekly, 20 June 2023 — GaGallium (Florian Angeletti), Jun 20, 2023
This series of blog posts aims to give a short weekly glimpse into my (Florian Angeletti) daily work on the OCaml compiler. This quiet week was focused on finishing ongoing tasks and discussing future collaborations.
A few finished tasks
Last week was a quiet week, in term of new activities. However, I was able to push few of my ongoing tasks over the finish line:
Semantic tag for inline code in the compiler
I have at last finalized this pull request that introduces an uniform quoting s…
Read more...This series of blog posts aims to give a short weekly glimpse into my (Florian Angeletti) daily work on the OCaml compiler. This quiet week was focused on finishing ongoing tasks and discussing future collaborations.
A few finished tasks
Last week was a quiet week, in term of new activities. However, I was able to push few of my ongoing tasks over the finish line:
Semantic tag for inline code in the compiler
I have at last finalized this pull request that introduces an uniform quoting style for inline code inside all the messages across the compilers. With more than 300 hundred source files (fortunately mostly tests) changed, this is the kind of Pull Request that one is glad to see merged. At the very least, because this means no more lengthy rebasing.
A type for symbol identifiers in the bytecode
Working with Sébastien Hinderer, I have completed a final review on his work on switching to a narrower type for global symbols in the bytecode backend. His PR has been merged on last Friday. Hopefully, it shall make further work in this area of the compiler simpler by making it clearer when global symbols are compilation unit names, or when they might be predefined exceptions.
ppxlib 0.30 ready to be
In the beginning of the week, I have spent some time with the ppxlib team to check that the new version of ppxlib (with the compatibility fix for the second alpha release of OCaml 5.1.0) is ready.
Once this new version of ppxlib is out-of-the-door, I will restart my survey of the state of the opam ecosystem before the release of the first beta for OCaml 5.1.0
Discussing future collaborations with Tarides
In parallel, I have been discussing with the benchmarking team and odoc team at Tarides on collaborating on two subjects in the medium term future:
Continuous benchmarks for the compiler
A common subject of interest with Tarides benchmarking team is to try to set us a pipeline for continuously monitoring the performance of the OCaml compiler.
Having such continuous monitoring would bring two major advantages from my perspective:
monitoring long term trends: a 0.1% weekly slowdown of the compiler speed might not be worth worrying. One year of accumulated 0.1% weekly slowdowns is worrying.
catching performance accident early: conversely, a significant unexpected drop or increase in a Pull Request is a worrying concern that we want to detect as early to possible to investigate (and possibly) the cause of this change
Better integration of the OCaml manual with ocaml.org
Currently, the integration of the OCaml manual and API documentation
within the ocaml.org is very barebone:
The main ocaml.org site links towards the old
v2.ocaml.org website where the manual is still hosted
through redirection.
This setup was supposed to be temporary, but I have not yet found the
time to improve this integration. I hope to fix this in time for the
release of OCaml 5.1.0 in July. In particular, this would be a good time
for transitioning the ocaml.org hosted API reference to the
odoc version which has been dormant hidden with the compiler repository
for few years now.
OCaml Receives the ACM SIGPLAN Programming Languages Software Award — Tarides, Jun 20, 2023
OCaml has received one of the most prestigious awards in the field of programming languages, and we are very thrilled that four of the award winners are from Tarides. This represents a huge success for the language, the named maintainers, and everyone who has worked on improving OCaml. We want to thank everyone for their hard work and celebrate the award alongside the OCaml community. Here’s to many more years of hacking together!
A Significant Impact on Building Better Software
The ACM specia…
Read more...OCaml has received one of the most prestigious awards in the field of programming languages, and we are very thrilled that four of the award winners are from Tarides. This represents a huge success for the language, the named maintainers, and everyone who has worked on improving OCaml. We want to thank everyone for their hard work and celebrate the award alongside the OCaml community. Here’s to many more years of hacking together!
A Significant Impact on Building Better Software
The ACM special interest group on programming languages, SIGPLAN, annually recognises significant developments in a software system and awards it with the Programming Languages Software Award. To be selected for this prestigious award, a software system must have made a significant impact on programming language research, implementation, and tools.
Previous recipients include WebAssembly, the first widely adopted language for web browsers since JavaScript; and Scala, one of the few programming languages from academia that has had a significant impact on the world as well as on programming languages research.
This year, fourteen developers in the open-source OCaml ecosystem have been recognised for their contributions to the design and implementation of the language. OCaml is a functional programming language that combines type and memory safety with powerful features like garbage collection and a type inferring compiler. Born out of extensive research into ML, OCaml was first released in 1996 by Xavier Leroy, Jérôme Vouillon, Damien Doligez, and Didier Rémy. Since then, the open-source community surrounding OCaml has grown (in parts, thanks to Tarides!) with new tools, libraries, and applications.
OCaml is unique because it occupies a sweet spot in the space of programming language designs. It provides a combination of efficiency, expressiveness and practicality that is matched by no other language. This is largely because OCaml is an elegant combination of language features developed over the last 60 years, with strong roots in academia and the industry. The language also continues to evolve and innovate, with the release of OCaml 5 last December. That release heralds a new era for OCaml by providing the infrastructure for programming efficiently and safely using multiple cores. OCaml 5 also added effect handlers to the language, which makes OCaml the first mainstream language with support with effects. Meanwhile, OCaml is now used for trading billions of dollars in global equity daily or for helping millions of daily users of Docker to access the network.
The engineers receiving this award have played a crucial role in the long-term development of the OCaml language. Their hard work has made OCaml a language that prioritises performance and expressivity while strongly focusing on security and safety. The fourteen developers named by ACM SIGPLAN are: David Allsopp, Florian Angeletti, Stephen Dolan, Damien Doligez, Alain Frisch, Jacques Garrigue, Anil Madhavapeddy, Luc Maranget, Nicolás Ojeda Bär, Gabriel Scherer, KC Sivaramakrishnan, Jérôme Vouillon, Leo White and Xavier Leroy.
It is well worth noting that Xavier Leroy already holds many prestigious awards for his work - he is a former recipient of the ACM SIGPLAN Programming Languages Achievement award in 2022, holds the chair of software science at Collège de France and is member of Académie des sciences. Xavier made pivotal contributions across various fields, including the design of type and module systems, bytecode verification, and verified compilation, to highlight a few. He is also the visionary architect of the CompCert C compiler, the first formally verified, high-assurance compiler for almost all of the C language. This enormous achievements generated entirely new areas of activity and research: CompCert won the 2022 ACM SIGPLAN Programming Languages Software award and the 2021 ACM Software Systems award. But Xavier's research contributions are not just integral to his illustrious career. They are also pivotal to OCaml's current success and widespread appeal. His active and ongoing influence is deeply embedded within OCaml, shaping it into the rigorous yet pragmatic language that it is today.
The Role of Tarides
Tarides is honoured to contribute to the development of OCaml and to be part of the vibrant ecosystem surrounding the language. Four of the developers receiving the award are affiliated with Tarides: David, KC, Jérôme and Anil!
The list of recipients comprises award-winning and internationally acclaimed academics (Inria, University of Cambridge, University of Nagoya, IIT Madras) as well as impactful and innovative industry professionals (Lexifi, Jane Street, Tarides). This list makes a compelling case for the model that guides the entire OCaml ecosystem and that we’ve adopted at Tarides. We combine the powers of academia, industry, and community hackers by collaborating for the benefit of OCaml as a whole.
Moreover, Tarides is a descendant of OCaml Labs at the University of Cambridge, a decade-long effort aiming to bring OCaml to the masses:KC, Stephen, Leo, and David all started off at the University of Cambridge, under the direction of Anil. Since then, OCaml Labs and now Tarides have dedicated much time and energy towards maintaining several parts of the OCaml ecosystem, including the compiler, platform tools, the CI infrastructure, and OCaml.org.
Finally, we want to acknowledge that this award recognises the hard work of people beyond just the list of winners. There are countless people who have contributed to OCaml, who taken together would be too numerous to formally recognise. Nevertheless, their hard work is palpable and their impact far-reaching, and we want to thank everyone who has played a role in bringing OCaml to where it is today. This achievement is one we all share with the entire community.
OCaml 5
As described in KC's keynote, OCaml 5.0 introduced much anticipated new features to OCaml, supporting shared memory parallelism and effect handlers. The team focused on making that release as backwards compatible as possible; thus, existing OCaml users could upgrade without experiencing breakage. OCaml 5 allows users to combine safety and security features with significant performance improvements, including parallel programming and improved methodologies for writing concurrent code.
If you want to learn how to use the parallelism features in OCaml 5, have a look at these tutorials on GitHub. For more details on exactly what changes OCaml 5 brought to OCaml, the changelog contains all the information you need.
HideContact Tarides to see how OCaml can benefit your business and/or for support while learning OCaml. Follow us on Twitter and LinkedIn to ensure you never miss a post, and join the OCaml discussion on Discuss!
Release of Frama-C 27.0 (Cobalt) — Frama-C, Jun 15, 2023
Isomorphism invariance and isomorphism reflection in type theory (TYPES 2023) — Andrej Bauer, Jun 14, 2023
At TYPES 2023 I had the honor of giving an invited talk “On Isomorphism Invariance and Isomorphism Reflection in Type Theory” in which I discussed isomorphism reflection, which states that isomorphic types are judgementally equal. This strange principle is consistent, and it validates some fairly strange type-theoretic statements.
Here are the slides with speaker notes and the video recording of the talk.
View older blog posts.
Syndications


- Ahrefs
- Andrej Bauer
- Andy Ray
- Ashish Agarwal
- CUFP
- Cameleon news
- Caml INRIA
- Caml Spotting
- Coherent Graphics
- Coq
- Cranial Burnout
- Daniel Bünzli
- Daniel Bünzli (log)
- Daniil Baturin
- David Baelde
- David Teller
- Erik de Castro Lopo
- Etienne Millon
- Frama-C
- GaGallium
- Gabriel Radanne
- Gerd Stolpmann
- Grant Rettke
- Hannes Mehnert
- Hong bo Zhang
- Jake Donham
- Jane Street
- KC Sivaramakrishnan
- Leo White
- Magnus Skjegstad
- Marc Simpson
- Matthias Puech
- Matías Giovannini
- Mike Lin
- Mike McClurg
- Mindy Preston
- OCaml Book
- OCaml Labs compiler hacking
- OCaml Platform
- OCaml-Java
- OCamlCore.com
- ODNS project
- Ocaml XMPP project
- Ocsigen project
- Opa
- Orbitz
- Paolo Donadeo
- Psellos
- Reason Documentation Blog
- Richard Jones
- Rudi Grinberg
- Sebastien Mondet
- Shayne Fletcher
- Stefano Zacchiroli
- Tarides
- The BAP Blog
- Thomas Leonard
- Till Varoquaux
- Xinuo Chen
- Yan Shvartzshnaider