Programmazione funzionale
Che cos'è la programmazione funzionale?
Ci siamo inoltrati abbastanza nel tutorial, ma ancora non abbiamo
realmente considerato la programmazione funzionale. Tutte le
caratteristiche date finora - ricchi tipi di dati, pattern matching,
inferenza dei tipi, funzioni annidate - si potrebbe immaginare che
esistessero in una specie di linguaggio "super C". Si tratta certamente
di Caratteristiche Forti, e che rendono il vostro codice conciso, facile
da leggere e con meno bug, ma che in realtà hanno ben poco a che fare
con la programmazione funzionale. In effetti il mio argomento sarà che
il motivo per cui i linguaggi funzionali sono così grandi non è il
fatto della programmazione funzionale, ma il fatto che ci siamo fissati
per anni con linguaggi del tipo di C e nel frattempo l'avanguardia della
programmazione si è spostata considerevolmente. Così, mentre noi
scrivevamo per l'ennesima volta struct { int type; union { ... } }, i
programmatori ML ed Haskell avevano varianti sicure e pattern matching
sui tipi di dati. Mentre facevamo attenzione a liberare con free tutti
i nostri malloc, esistevano fin dagli anni '80 linguaggi con garbage
collector capaci di far meglio del codice scritto a mano.
Bene, dopo questo è meglio che vi dica che cos'è in ogni caso la programmazione funzionale.
La definizione di base, non molto illuminante, è la seguente: in un linguaggio funzionale, le funzioni sono cittadini di prima classe.
Tante parole che in realtà non dànno molto il senso. Facciamo allora un esempio:
# let double x =
x * 2 in
List.map double [ 1; 2; 3 ];;
- : int list = [2; 4; 6]
In questo esempio, ho per prima cosa definito una funzione annidata
chiamata double che prende un argomento x e restituisce x * 2.
Quindi map chiama double su ciascun elemento della lista data
([1; 2; 3]) per produrre un risultato: una lista con ciascun numero
raddoppiato.
map è conosciuta come funzione di ordine superiore (HOF,
higher-order function). Le funzioni di ordine superiore sono
semplicemente un modo fantasioso per dire che la funzione prende una
funzione come uno dei suoi argomenti.
Finora tutto semplice. Se siete familiari con C/C++ questo sembra come
passare un puntatore di funzione. Java ha una sorta di abominio chiamato
classe anonimca che è come una closure semplificata, lunga e verbosa. Se
conoscete Perl probabilmente già conoscete ed utilizzate le closure di
Perl e la funzione map di Perl, che è esattamente ciò di cui stiamo
parlando. Il fatto è che Perl è in realtà abbastanza piuttosto buono
come linguaggio funzionale.
Le closure sono funzioni che si portano dietro qualcosa
dell'"ambiente" in cui sono definite. In particolare, una closure può
fare riferimento a variabili che siano disponibili al punto della sua
definizione. Generalizziamo la funzione sopra così da poter ora prendere
una lista di interi e moltiplicare ciascun elemento per un valore
arbitrario n:
# let multiply n list =
let f x =
n * x in
List.map f list;;
val multiply : int -> int list -> int list = <fun>
Da cui:
# multiply 2 [1; 2; 3];;
- : int list = [2; 4; 6]
# multiply 5 [1; 2; 3];;
- : int list = [5; 10; 15]
Il punto importante da notare riguardo la funzione multiply è la
funzione annidata f. Questa è una closure. Osserviamo come f usi il
valore di n, il quale non è effettivamente passato come argomento
esplicito a f. Invece f lo prende dal suo ambiente - è un argomento
della funzione multiply e dunque disponibile entro tale funzione.
Ciò potrebbe suonare abbastanza ovvio, ma guardiamo più da vicino quella
chiamata a map: List.map f list.
map è definita all'interno del modulo List module, lontano dal
corrente codice. In altre parole, stiamo passando f in un modulo
definito "tanto tempo fa, in una galassia lontana lontana". Per quello
che sappiamo quel codice potrebbe passare f ad altri moduli, o salvare
in qualche posto un riferimento a f e chiamarlo più tardi. Che lo
faccia o no, la closure assicurerà che f abbia sempre accesso al suo
ambiente paterno, e a n.
Ecco un esempio reale da lablgtk. Si tratta in realtà di un metodo su una classe (non abbiamo ancora parlato delle clessi e degli oggetti, ma per ora pensatelo semplicemente come una definizione di funzione).
class html_skel obj = object (self)
...
...
method save_to_channel chan =
let receiver_fn content =
output_string chan content;
true
in
save obj receiver_fnPrima di tutto dovete sapere che la funzione save chiamata alla fine
del metodo prende come suo secondo argomento una funzione
(receiver_fn). Essa chiama ripetutamente receiver_fn con parti di
testo dello strumento che sta cercando di salvare.
Osservate ora la definizione di receiver_fn. Questa funzione è una
closure in piena regola poiché prende un riferimento a chan dal suo
ambiente.
Applicazioni parziali di funzioni e currying
Definiamo una funzione plus che somma semplicemente due interi:
# let plus a b =
a + b;;
val plus : int -> int -> int = <fun>
Qualche domanda per la gente che dorme in fondo alla classe.
- Che cos'è
plus? - Che cos'è
plus 2 3? - Che cos'è
plus 2?
La domanda 1 è facile. plus è una funzione, prende due argomenti che
sono interi e restituisce un intero. Scriviamo il suo tipo come:
plus : int -> int -> intLa domanda 2 è ancora più facile. plus 2 3 è un numero, l'intero 5.
Ne scriviamo il valore e il tipo così:
5 : intMa che dire della domanda 3? Pare che plus 2 sia un errore, un bug. Di
fatto, tuttavia, non lo è. Se lo scriviamo nel toplevel di OCaml, esso
ci dice:
# plus 2;;
- : int -> int = <fun>
Questo non è un errore. Ci sta dicecndo che plus 2 è di fatto una
funzione, che prende un int e restituisce un int. Che sorta di
funzione è questa? Sperimentiamo per prima cosa dando a questa
misteriosa funzione un nome (f), e quindi provandola su degli interi
per vedere che cosa fa:
# let f = plus 2;;
val f : int -> int = <fun>
# f 10;;
- : int = 12
# f 15;;
- : int = 17
# f 99;;
- : int = 101
In ingegneria questa è per noi una sufficiente prova attraverso
esempio
perché possiamo stabilire che plus 2 è la funzione che aggiunge 2 alle
cose.
Tornando alla definizione originale, "riempiamo" il primo argomento
(a) impostandolo a 2 per avere:
let plus 2 b = (* Questo non è codice OCaml reale! *)
2 + bPotete in qualche modo vedere, spero, perché plus 2 è la funzione che
aggiunge 2 alle cose.
Osservando i tipi di queste espressioni potremmo riuscire a scorgere qualche fondamento per la strana notazione a freccia -> usata per i tipi di funzione:
plus : int -> int -> int
plus 2 : int -> int
plus 2 3 : intQuesto processo è detto currying (o forse è detto uncurrying, non sono mai stato davvero certo di cosa fosse cosa). Si chiama così da Haskell Curry che fece delle cose importanti relative al calcolo lambda. Visto che sto cercando di evitare di entrare nel campo della matematica al di là di OCaml poiché ciò renderebbe il tutorial assai noioso ed irrilevante, non andrò oltre sull'argomento. Potete trovare molte più informazioni sul currying se vi interessa con una ricerca su Google.
Ricordate da prima le nostre funzioni double e multiply? multiply
era stata definita così:
# let multiply n list =
let f x =
n * x in
List.map f list;;
val multiply : int -> int list -> int list = <fun>
Possiamo ora definire funzioni double, triple & co. molto
facilmente, semplicemente così:
# let double = multiply 2;;
val double : int list -> int list = <fun>
# let triple = multiply 3;;
val triple : int list -> int list = <fun>
Sono realmente funzioni, osservate:
# double [1; 2; 3];;
- : int list = [2; 4; 6]
# triple [1; 2; 3];;
- : int list = [3; 6; 9]
Potete anche utilizzare direttamente l'applicazione parziale (senza la
funzione intermedia f) così:
# let multiply n = List.map (( * ) n);;
val multiply : int -> int list -> int list = <fun>
# let double = multiply 2;;
val double : int list -> int list = <fun>
# let triple = multiply 3;;
val triple : int list -> int list = <fun>
# double [1; 2; 3];;
- : int list = [2; 4; 6]
# triple [1; 2; 3];;
- : int list = [3; 6; 9]
Nell'esempio sopra, ((*) n) è l'applicazione parziale della funzione
(*) (times). Si notino gli spazi extra necessari perché OCaml non
pensi che (* cominci un commmento.
Per fare funzioni potete usare operatori "infix" tra parentesi tonde.
Ecco una definizione di plus identica a quella sopra:
# let plus = (+);;
val plus : int -> int -> int = <fun>
# plus 2 3;;
- : int = 5
Ecco qualche altro gioco di currying:
# List.map (plus 2) [1; 2; 3];;
- : int list = [3; 4; 5]
# let list_of_functions = List.map plus [1; 2; 3];;
val list_of_functions : (int -> int) list = [<fun>; <fun>; <fun>]
Per che cosa è buona la programmazione funzionale?
La programmazione funzionale, come ogni buona tecnica di programmazione,
è uno strumento utile nel vostro arsenale per la risoluzione di alcune
classi di problemi. È molto buona per le chiamate ripetute, che hanno
molteplici utilizzi dalle GUI fino ai loop guidati da eventi. È grande
per esprimere algoritmi generici. List.map è proprio un algoritmo
generico per l'applicazione di funzioni su qualsivoglia tipo di lista.
In modo simile potete definire funzioni generiche sugli alberi. Alcuni
tipi di problemi numerici possono essere risolti molto rapidamente con
la programmazione funzionale (per esempio, il calcolo numerico della
derivata di una funzione matematica).
Programmazione funzionale pura e impura
Una funzione pura è una funzione senza alcun effetto laterale
(side-effect). Un effetto laterale significa nella realtà che la
funzione tiene al suo interno una qualche sorta di stato nascosto.
strlen è un buon esempio di funzione pura in C. Se chiamate strlen
con la medesima stringa, essa restituisce sempre la medesima lunghezza.
L'output di strlen (la lunghezza) dipende soltanto dagli input (la
stringa) e da null'altro. Molte funzioni in C sono, sfortunatamente,
impure. Per esempio, malloc - se la chiamate con il medesimo numero,
certamente non vi restituirà il medesimo puntatore. malloc,
naturalmente, dipende da un enorme numero di stati interni nascosti
(oggetti allocati nel mucchio, il metodo di allocazione in uso, prendere
pagine dal sistema operativo, etc.).
I linguaggi derivati da ML come OCaml sono "per lo più puri". Consentono effetti laterali attraverso cose come i riferimenti e gli array, ma in linea di massima la maggior parte del codice che scriverete sarà puramente funzionale, poiché essi incoraggiano questo modo di pensare. Haskell, un altro linguaggio funzionale, è puramente funzionale. OCaml è dunque più pratico poiché a volte è utile scrivere funzioni impure.
Vi sono varii vantaggi teorici nell'avere funzioni pure. Un vantaggio è che se una funzione è pura, se è chiamata più volte con i medesimi argomenti, il compilatore deve chiamare effettivamente la funzione una sola volta. Un buon esempio in C è:
for (i = 0; i < strlen (s); ++i)
{
// Fai qualcosa che non interessa s.
}Se compilato ingenuamente, questo ciclo è O(n^2^) poiché strlen (s) è
chiamata ogni volta e strlen deve fare un'iterazione su tutta s. Se
il compilatore è abbastanza intelligente per dedurre che strlen è
puramente funzionale e che s non è aggiornata nel ciclo, esso può
rimuovere le chiamate extra ridondanti a strlen e rendere il ciclo
O(n). I compilatori lo fanno realmente? Nel caso di strlen sì, in
altri casi probabilmente no.
Concentrarvi sullo scrivere piccole funzioni pure vi consente di costruire codice riutilizzabile utilizzando un approccio bottom-up, testando ciascuna piccola funzione mentre procedete. La tendenza attuale è quella di pianificare accuratamente i propri programmi utilizzando un approccio top-down, ma nell'opinione dell'autore questo ha spesso per effetto il fallimento di progetti.
Severità e pigrizia
I linguaggi derivati da C e quelli derivati da ML sono "strict" ("severi"). Haskell e Miranda sono linguaggi "non-strict", o "lazy" ("pigri"). OCaml è normalmente strict ma consente uno stile lazy di programmazione quando è necessario.
In un linguaggio strict, sono sempre prima valutati gli argomenti delle funzioni, e i risultati sono quindi passati alla funzione. Ad esempio in un linguaggio strict questa chiamata risulterà sempre in un errore di divisione per zero:
# let give_me_a_three _ = 3;;
val give_me_a_three : 'a -> int = <fun>
# give_me_a_three (1/0);;
Exception: Division_by_zero.
Se avete programmato in un linguaggio convenzionale, le cose vanno proprio così, e sareste sorpresi se le cose potessero andare diversamente.
In un linguaggio lazy accade qualcosa di più particolare. Gli argomenti
delle funzioni sono valutati soltanto se la funzione li usa realmente.
Ricordate che la funzione give_me_a_three getta via il suo argomento e
restituisce sempre un 3? Ebbene in un linguaggio lazy la chiamata sopra
non può fallire poiché give_me_a_three non guarda mai il suo primo
argomento, così che il primo argomento non è mai valutato, dunque la
divisione per zero non avviene.
I linguaggi lazy vi consentono anche di fare cose davvero strane come definire ina lista infinitamente lunga. Questo funziona a patto che non tentiate realmente un'iterazione sull'intera lista (diciamo, invece, che tentate soltanto di estrarre i primi 10 elementi).
OCaml è un linguaggio strict, ma ha un modulo Lazy che vi lascia
scrivere espressioni lazy. Ecco un esempio. Creiamo per prima cosa
un'espressione lazy per 1/0:
# let lazy_expr = lazy (1/0);;
val lazy_expr : int lazy_t = <lazy>
Notate che il tipo di questa espressione lazy è int lazy_t.
Poiché give_me_a_three prende 'a (un tipo) possiamo passare questa
espressione lazy nella funzione:
# give_me_a_three lazy_expr;;
- : int = 3
Per valutare un'espressione lazy, dovete usare la funzione Lazy.force:
# Lazy.force lazy_expr;;
Exception: Division_by_zero.
Tipi boxed e unboxed
Un termine che sentirete spesso discutendo di linguaggi funzionali è "boxed". Ero molto comfuso quando ho sentito per la prima volta questo termine, ma di fatto la distinzione fra tipi boxed ed unboxed è piuttosto semplice se avete usato in precedenza C, C++ o Java (in Perl, tutto è boxed).
Il modo di pensare ad un oggetto boxed è quello di pensare ad un oggetto
che è stato allocato sul mucchio attraverso malloc in C (o in modo
equivalente new in C++), e/o è referenziato attraverso un puntatore.
Diamo uno sguardo a questo programma C di esempio:
#include <stdio.h>
void
printit (int *ptr)
{
printf ("the number is %d\n", *ptr);
}
void
main ()
{
int a = 3;
int *p = &a;
printit (p);
}La variabile a è allocata sullo stack, ed è in definitiva unboxed.
La funzione printit prende un integer boxed e lo stampa.
Il diagramma sotto mostra un array di interi unboxed (sopra) e boxed (sotto):
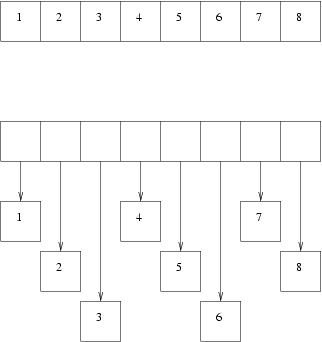
Non si vince nulla ad indovinare che l'array di interi unboxed è molto più veloce dell'array di interi boxed. In più, poiché vi sono meno allocazioni separate, la garbage collection è molto più veloce e più semplice sull'array di oggetti.
In C o C++ non dovreste aver problemi nel costruire uno dei due tipi
sopra. In Java, avete due tipi, int che è unboxed e Integer che è
boxed, e dunque considerevolmente meno efficiente. In OCaml, i tipi di
base sono tutti unboxed.